 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
Lesion-Aware Cross-Phase Attention Network for Renal Tumor Subtype Classification on Multi-Phase CT Scans
Jun 24, 2024Multi-phase computed tomography (CT) has been widely used for the preoperative diagnosis of kidney cancer due to its non-invasive nature and ability to characterize renal lesions. However, since enhancement patterns of renal lesions across CT phases are different even for the same lesion type, the visual assessment by radiologists suffers from inter-observer variability in clinical practice. Although deep learning-based approaches have been recently explored for differential diagnosis of kidney cancer, they do not explicitly model the relationships between CT phases in the network design, limiting the diagnostic performance. In this paper, we propose a novel lesion-aware cross-phase attention network (LACPANet) that can effectively capture temporal dependencies of renal lesions across CT phases to accurately classify the lesions into five major pathological subtypes from time-series multi-phase CT images. We introduce a 3D inter-phase lesion-aware attention mechanism to learn effective 3D lesion features that are used to estimate attention weights describing the inter-phase relations of the enhancement patterns. We also present a multi-scale attention scheme to capture and aggregate temporal patterns of lesion features at different spatial scales for further improvement. Extensive experiments on multi-phase CT scans of kidney cancer patients from the collected dataset demonstrate that our LACPANet outperforms state-of-the-art approaches in diagnostic accuracy.
* This article has been accepted for publication in Computers in Biology and Medicine
A Unified Multi-Phase CT Synthesis and Classification Framework for Kidney Cancer Diagnosis with Incomplete Data
Dec 09, 2023Multi-phase CT is widely adopted for the diagnosis of kidney cancer due to the complementary information among phases. However, the complete set of multi-phase CT is often not available in practical clinical applications. In recent years, there have been some studies to generate the missing modality image from the available data. Nevertheless, the generated images are not guaranteed to be effective for the diagnosis task. In this paper, we propose a unified framework for kidney cancer diagnosis with incomplete multi-phase CT, which simultaneously recovers missing CT images and classifies cancer subtypes using the completed set of images. The advantage of our framework is that it encourages a synthesis model to explicitly learn to generate missing CT phases that are helpful for classifying cancer subtypes. We further incorporate lesion segmentation network into our framework to exploit lesion-level features for effective cancer classification in the whole CT volumes. The proposed framework is based on fully 3D convolutional neural networks to jointly optimize both synthesis and classification of 3D CT volumes. Extensive experiments on both in-house and external datasets demonstrate the effectiveness of our framework for the diagnosis with incomplete data compared with state-of-the-art baselines. In particular, cancer subtype classification using the completed CT data by our method achieves higher performance than the classification using the given incomplete data.
* This article has been accepted for publication in IEEE Journal of Biomedical and Health Informatics
Exploring 3D U-Net Training Configurations and Post-Processing Strategies for the MICCAI 2023 Kidney and Tumor Segmentation Challenge
Dec 09, 2023


In 2023, it is estimated that 81,800 kidney cancer cases will be newly diagnosed, and 14,890 people will die from this cancer in the United States. Preoperative dynamic contrast-enhanced abdominal computed tomography (CT) is often used for detecting lesions. However, there exists inter-observer variability due to subtle differences in the imaging features of kidney and kidney tumors. In this paper, we explore various 3D U-Net training configurations and effective post-processing strategies for accurate segmentation of kidneys, cysts, and kidney tumors in CT images. We validated our model on the dataset of the 2023 Kidney and Kidney Tumor Segmentation (KiTS23) challenge. Our method took second place in the final ranking of the KiTS23 challenge on unseen test data with an average Dice score of 0.820 and an average Surface Dice of 0.712.
Image Generation with Self Pixel-wise Normalization
Jan 26, 2022Region-adaptive normalization (RAN) methods have been widely used in the generative adversarial network (GAN)-based image-to-image translation technique. However, since these approaches need a mask image to infer the pixel-wise affine transformation parameters, they cannot be applied to the general image generation models having no paired mask images. To resolve this problem, this paper presents a novel normalization method, called self pixel-wise normalization (SPN), which effectively boosts the generative performance by performing the pixel-adaptive affine transformation without the mask image. In our method, the transforming parameters are derived from a self-latent mask that divides the feature map into the foreground and background regions. The visualization of the self-latent masks shows that SPN effectively captures a single object to be generated as the foreground. Since the proposed method produces the self-latent mask without external data, it is easily applicable in the existing generative models. Extensive experiments on various datasets reveal that the proposed method significantly improves the performance of image generation technique in terms of Frechet inception distance (FID) and Inception score (IS).
Rethinking Coarse-to-Fine Approach in Single Image Deblurring
Aug 11, 2021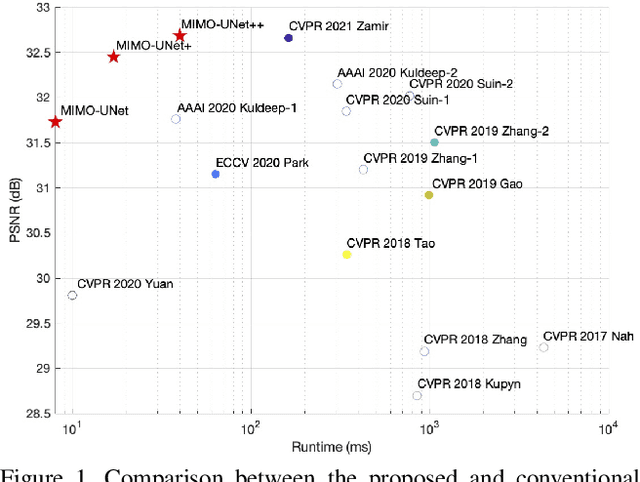

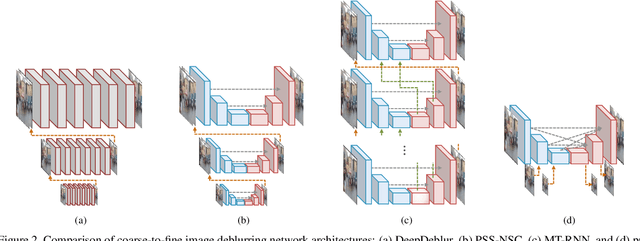
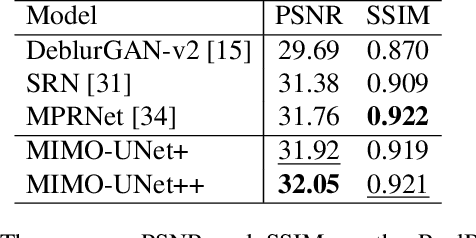
Coarse-to-fine strategies have been extensively used for the architecture design of single image deblurring networks. Conventional methods typically stack sub-networks with multi-scale input images and gradually improve sharpness of images from the bottom sub-network to the top sub-network, yielding inevitably high computational costs. Toward a fast and accurate deblurring network design, we revisit the coarse-to-fine strategy and present a multi-input multi-output U-net (MIMO-UNet). The MIMO-UNet has three distinct features. First, the single encoder of the MIMO-UNet takes multi-scale input images to ease the difficulty of training. Second, the single decoder of the MIMO-UNet outputs multiple deblurred images with different scales to mimic multi-cascaded U-nets using a single U-shaped network. Last, asymmetric feature fusion is introduced to merge multi-scale features in an efficient manner. Extensive experiments on the GoPro and RealBlur datasets demonstrate that the proposed network outperforms the state-of-the-art methods in terms of both accuracy and computational complexity. Source code is available for research purposes at https://github.com/chosj95/MIMO-UNet.
Content-aware Directed Propagation Network with Pixel Adaptive Kernel Attention
Jul 28, 2021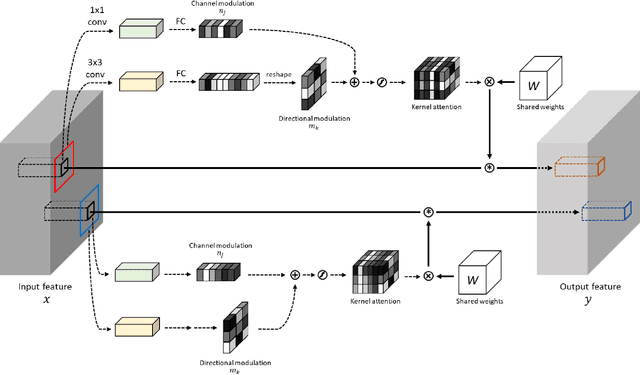
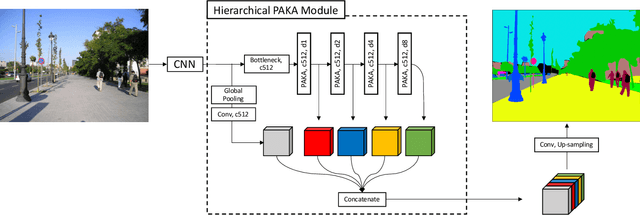
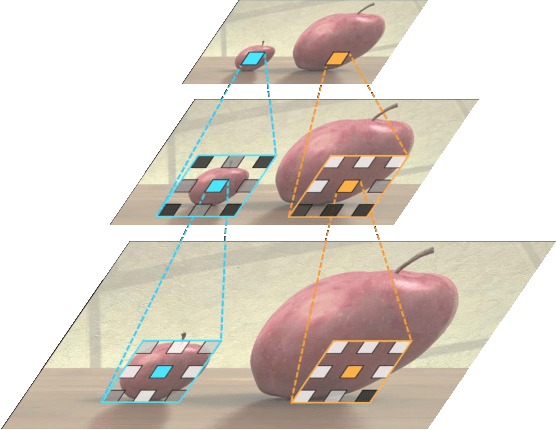
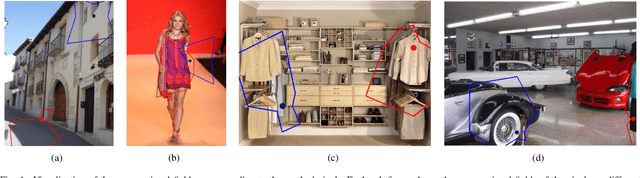
Convolutional neural networks (CNNs) have been not only widespread but also achieved noticeable results on numerous applications including image classification, restoration, and generation. Although the weight-sharing property of convolutions makes them widely adopted in various tasks, its content-agnostic characteristic can also be considered a major drawback. To solve this problem, in this paper, we propose a novel operation, called pixel adaptive kernel attention (PAKA). PAKA provides directivity to the filter weights by multiplying spatially varying attention from learnable features. The proposed method infers pixel-adaptive attention maps along the channel and spatial directions separately to address the decomposed model with fewer parameters. Our method is trainable in an end-to-end manner and applicable to any CNN-based models. In addition, we propose an improved information aggregation module with PAKA, called the hierarchical PAKA module (HPM). We demonstrate the superiority of our HPM by presenting state-of-the-art performance on semantic segmentation compared to the conventional information aggregation modules. We validate the proposed method through additional ablation studies and visualizing the effect of PAKA providing directivity to the weights of convolutions. We also show the generalizability of the proposed method by applying it to multi-modal tasks especially color-guided depth map super-resolution.
A Simple yet Effective Way for Improving the Performance of GANs
Dec 11, 2019

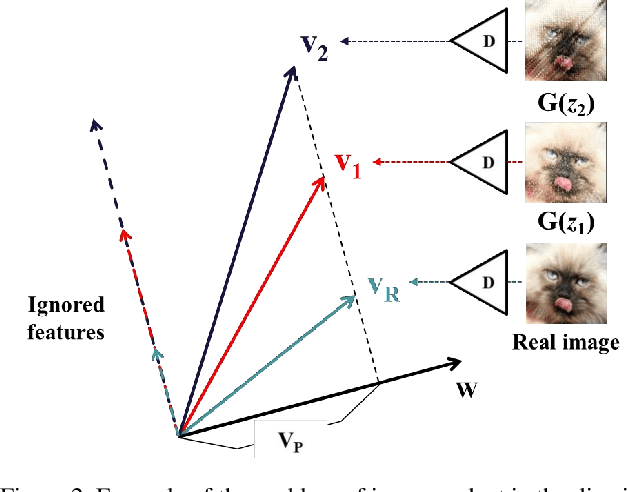

This paper presents a simple but effective way that improves the performance of generative adversarial networks (GANs) without imposing the training overhead or modifying the network architectures of existing methods. The proposed method employs a novel cascading rejection (CR) module for discriminator, which extracts multiple non-overlapped features in an iterative manner. The CR module supports the discriminator to effectively distinguish between real and generated images, which results in a strong penalization to the generator. In order to deceive the robust discriminator containing the CR module, the generator produces the images that are more similar to the real images. Since the proposed CR module requires only a few simple vector operations, it can be readily applied to existing frameworks with marginal training overheads. Quantitative evaluations on various datasets including CIFAR-10, Celeb-HQ, LSUN, and tiny-ImageNet confirm that the proposed method significantly improves the performance of GANs and conditional GANs in terms of Frechet inception distance (FID) indicating the diversity and visual appearance of the generated images.
W-Net: Two-stage U-Net with misaligned data for raw-to-RGB mapping
Nov 22, 2019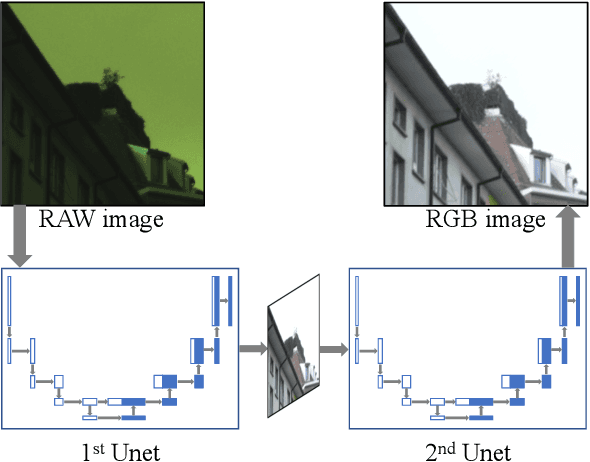
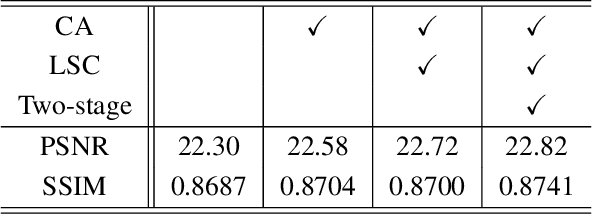
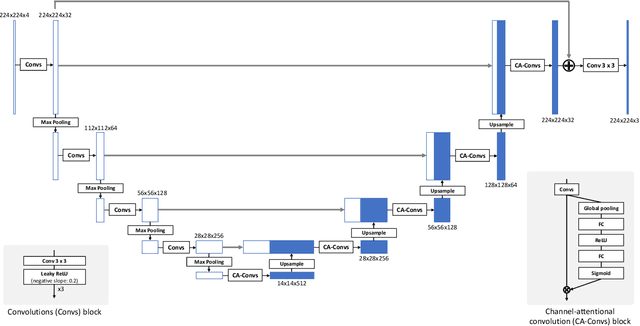

Recent research on learning a mapping between raw Bayer images and RGB images has progressed with the development of deep convolutional neural networks. A challenging data set namely the Zurich Raw-to-RGB data set (ZRR) has been released in the AIM 2019 raw-to-RGB mapping challenge. In ZRR, input raw and target RGB images are captured by two different cameras and thus not perfectly aligned. Moreover, camera metadata such as white balance gains and color correction matrix are not provided, which makes the challenge more difficult. In this paper, we explore an effective network structure and a loss function to address these issues. We exploit a two-stage U-Net architecture and also introduce a loss function that is less variant to alignment and more sensitive to color differences. In addition, we show an ensemble of networks trained with different loss functions can bring a significant performance gain. We demonstrate the superiority of our method by achieving the highest score in terms of both the peak signal-to-noise ratio and the structural similarity and obtaining the second-best mean-opinion-score in the challenge.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019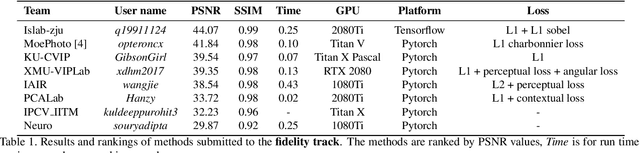
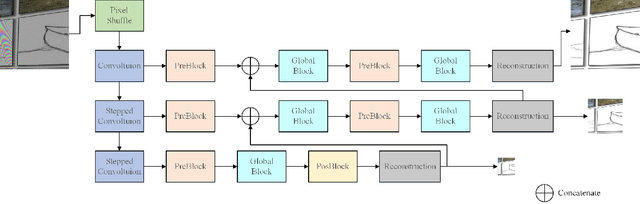
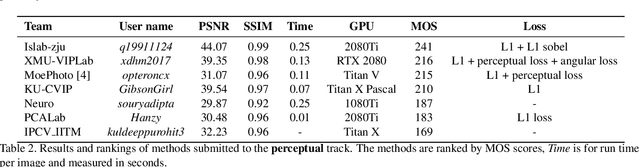
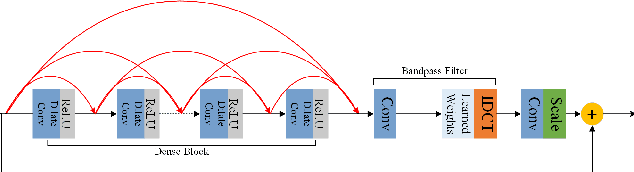
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.