 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Level AirComp for Wireless Federated Learning under Data Scarcity and Heterogeneity
Jun 06, 2025The conventional FL methods face critical challenges in realistic wireless edge networks, where training data is both limited and heterogeneous, often leading to unstable training and poor generalization. To address these challenges in a principled manner, we propose a novel wireless FL framework grounded in Bayesian inference. By virtue of the Bayesian approach, our framework captures model uncertainty by maintaining distributions over local weights and performs distribution-level aggregation of local distributions into a global distribution. This mitigates local overfitting and client drift, thereby enabling more reliable inference. Nevertheless, adopting Bayesian FL increases communication overhead due to the need to transmit richer model information and fundamentally alters the aggregation process beyond simple averaging. As a result, conventional Over-the-Air Computation (AirComp), widely used to improve communication efficiency in standard FL, is no longer directly applicable. To overcome this limitation, we design a dedicated AirComp scheme tailored to Bayesian FL, which efficiently aggregates local posterior distributions at the distribution level by exploiting the superposition property of wireless channels. In addition, we derive an optimal transmit power control strategy, grounded in rigorous convergence analysis, to accelerate training under power constraints. Our analysis explicitly accounts for practical wireless impairments such as fading and noise, and provides theoretical guarantees for convergence. Extensive simulations validate the proposed framework, demonstrating significant improvements in test accuracy and calibration performance over conventional FL methods, particularly in data-scarce and heterogeneous environments.
Rethinking Coarse-to-Fine Approach in Single Image Deblurring
Aug 11, 2021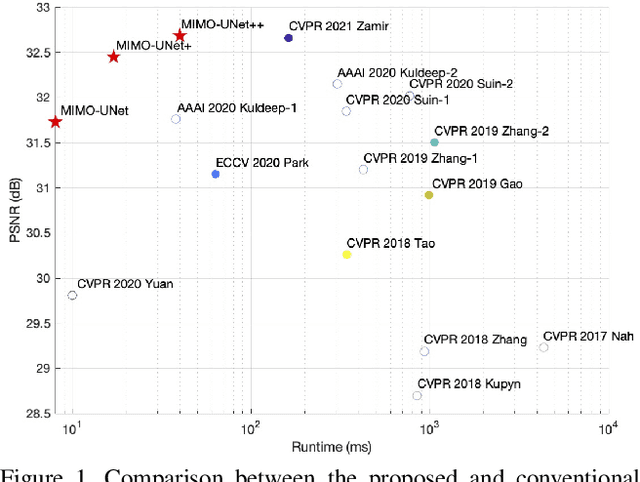

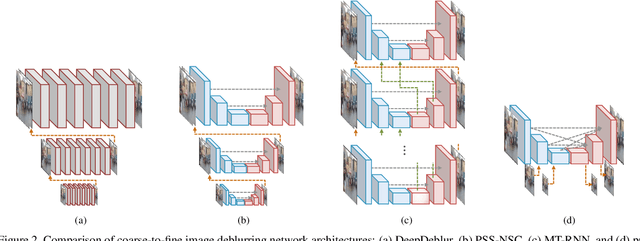
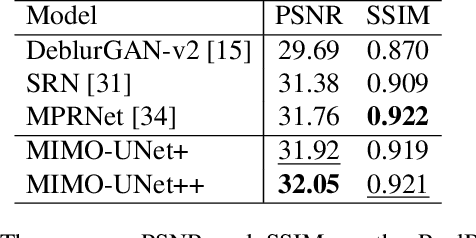
Coarse-to-fine strategies have been extensively used for the architecture design of single image deblurring networks. Conventional methods typically stack sub-networks with multi-scale input images and gradually improve sharpness of images from the bottom sub-network to the top sub-network, yielding inevitably high computational costs. Toward a fast and accurate deblurring network design, we revisit the coarse-to-fine strategy and present a multi-input multi-output U-net (MIMO-UNet). The MIMO-UNet has three distinct features. First, the single encoder of the MIMO-UNet takes multi-scale input images to ease the difficulty of training. Second, the single decoder of the MIMO-UNet outputs multiple deblurred images with different scales to mimic multi-cascaded U-nets using a single U-shaped network. Last, asymmetric feature fusion is introduced to merge multi-scale features in an efficient manner. Extensive experiments on the GoPro and RealBlur datasets demonstrate that the proposed network outperforms the state-of-the-art methods in terms of both accuracy and computational complexity. Source code is available for research purposes at https://github.com/chosj95/MIMO-UNet.
W-Net: Two-stage U-Net with misaligned data for raw-to-RGB mapping
Nov 22, 2019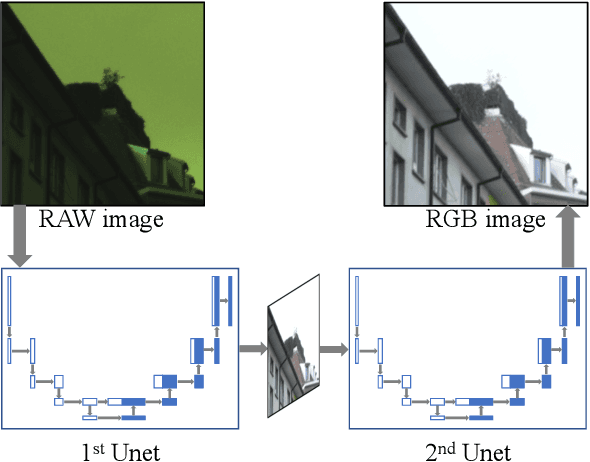
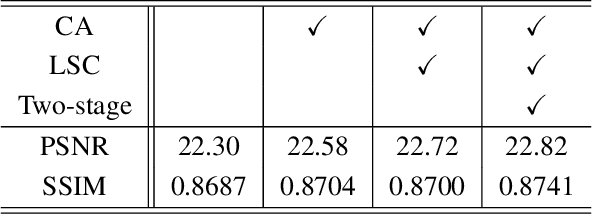
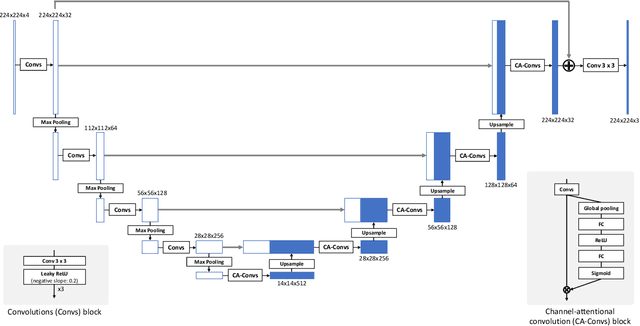

Recent research on learning a mapping between raw Bayer images and RGB images has progressed with the development of deep convolutional neural networks. A challenging data set namely the Zurich Raw-to-RGB data set (ZRR) has been released in the AIM 2019 raw-to-RGB mapping challenge. In ZRR, input raw and target RGB images are captured by two different cameras and thus not perfectly aligned. Moreover, camera metadata such as white balance gains and color correction matrix are not provided, which makes the challenge more difficult. In this paper, we explore an effective network structure and a loss function to address these issues. We exploit a two-stage U-Net architecture and also introduce a loss function that is less variant to alignment and more sensitive to color differences. In addition, we show an ensemble of networks trained with different loss functions can bring a significant performance gain. We demonstrate the superiority of our method by achieving the highest score in terms of both the peak signal-to-noise ratio and the structural similarity and obtaining the second-best mean-opinion-score in the challenge.