 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Edge Networks: Decentralized Learning Over Wireless Fronthaul
Dec 03, 2023



This paper studies task-oriented edge networks where multiple edge internet-of-things nodes execute machine learning tasks with the help of powerful deep neural networks (DNNs) at a network cloud. Separate edge nodes (ENs) result in a partially observable system where they can only get partitioned features of the global network states. These local observations need to be forwarded to the cloud via resource-constrained wireless fronthual links. Individual ENs compress their local observations into uplink fronthaul messages using task-oriented encoder DNNs. Then, the cloud carries out a remote inference task by leveraging received signals. Such a distributed topology requests a decentralized training and decentralized execution (DTDE) learning framework for designing edge-cloud cooperative inference rules and their decentralized training strategies. First, we develop fronthaul-cooperative DNN architecture along with proper uplink coordination protocols suitable for wireless fronthaul interconnection. Inspired by the nomographic function, an efficient cloud inference model becomes an integration of a number of shallow DNNs. This modulized architecture brings versatile calculations that are independent of the number of ENs. Next, we present a decentralized training algorithm of separate edge-cloud DNNs over downlink wireless fronthaul channels. An appropriate downlink coordination protocol is proposed, which backpropagates gradient vectors wirelessly from the cloud to the ENs.
W-Net: Two-stage U-Net with misaligned data for raw-to-RGB mapping
Nov 22, 2019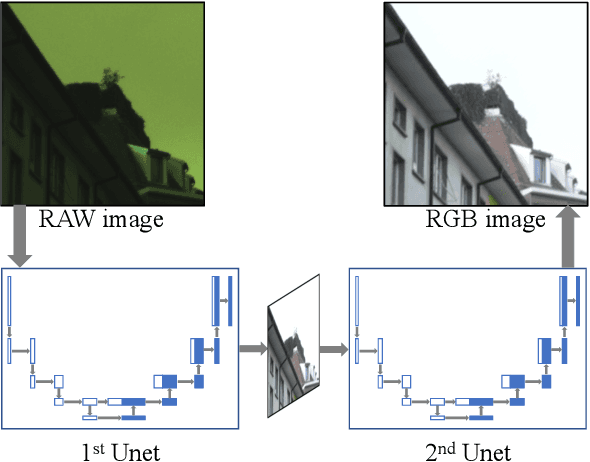
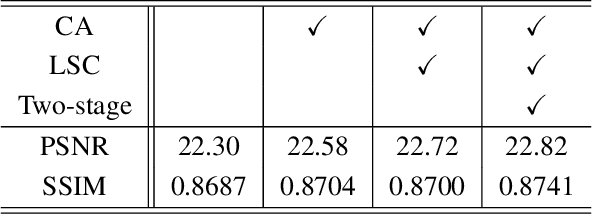
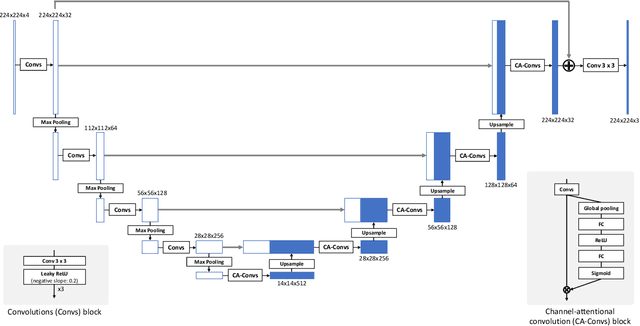

Recent research on learning a mapping between raw Bayer images and RGB images has progressed with the development of deep convolutional neural networks. A challenging data set namely the Zurich Raw-to-RGB data set (ZRR) has been released in the AIM 2019 raw-to-RGB mapping challenge. In ZRR, input raw and target RGB images are captured by two different cameras and thus not perfectly aligned. Moreover, camera metadata such as white balance gains and color correction matrix are not provided, which makes the challenge more difficult. In this paper, we explore an effective network structure and a loss function to address these issues. We exploit a two-stage U-Net architecture and also introduce a loss function that is less variant to alignment and more sensitive to color differences. In addition, we show an ensemble of networks trained with different loss functions can bring a significant performance gain. We demonstrate the superiority of our method by achieving the highest score in terms of both the peak signal-to-noise ratio and the structural similarity and obtaining the second-best mean-opinion-score in the challenge.
PEPSI++: Fast and Lightweight Network for Image Inpainting
May 22, 2019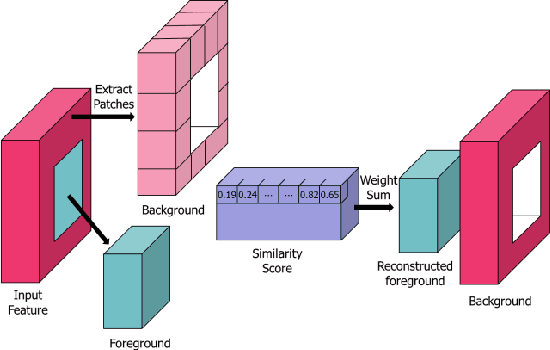
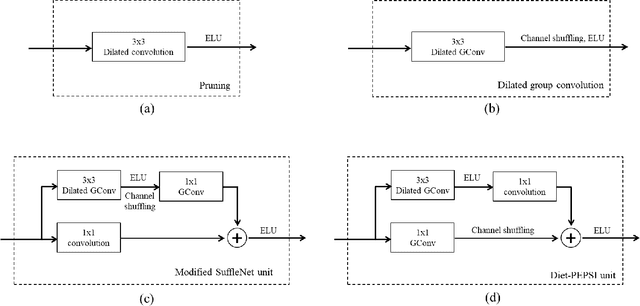


Generative adversarial network (GAN)-based image inpainting methods which utilize coarse-to-fine network with a contextual attention module (CAM) have shown remarkable performance. However, they require numerous computational resources such as convolution operations and network parameters due to two stacked generative networks, which results in a low speed. To address this problem, we propose a novel network structure called PEPSI: parallel extended-decoder path for semantic inpainting network, which aims at not only reducing hardware costs but also improving the inpainting performance. The PEPSI consists of a single shared encoding network and parallel decoding networks with coarse and inpainting paths. The coarse path generates a preliminary inpainting result to train the encoding network for prediction of features for the CAM. At the same time, the inpainting path results in higher inpainting quality with refined features reconstructed using the CAM. In addition, we propose a Diet-PEPSI which significantly reduces the network parameters while maintaining the performance. In the proposed method, we present a Diet-PEPSI unit (DPU) which effectively aggregates the global contextual information with a small number of parameters. Extensive experiments and comparisons with state-of-the-art image inpainting methods demonstrate that both PEPSI and Diet-PEPSI achieve significant improvements in qualitative scores and reduced computation cost.