 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Generation with Self Pixel-wise Normalization
Jan 26, 2022Region-adaptive normalization (RAN) methods have been widely used in the generative adversarial network (GAN)-based image-to-image translation technique. However, since these approaches need a mask image to infer the pixel-wise affine transformation parameters, they cannot be applied to the general image generation models having no paired mask images. To resolve this problem, this paper presents a novel normalization method, called self pixel-wise normalization (SPN), which effectively boosts the generative performance by performing the pixel-adaptive affine transformation without the mask image. In our method, the transforming parameters are derived from a self-latent mask that divides the feature map into the foreground and background regions. The visualization of the self-latent masks shows that SPN effectively captures a single object to be generated as the foreground. Since the proposed method produces the self-latent mask without external data, it is easily applicable in the existing generative models. Extensive experiments on various datasets reveal that the proposed method significantly improves the performance of image generation technique in terms of Frechet inception distance (FID) and Inception score (IS).
Content-aware Directed Propagation Network with Pixel Adaptive Kernel Attention
Jul 28, 2021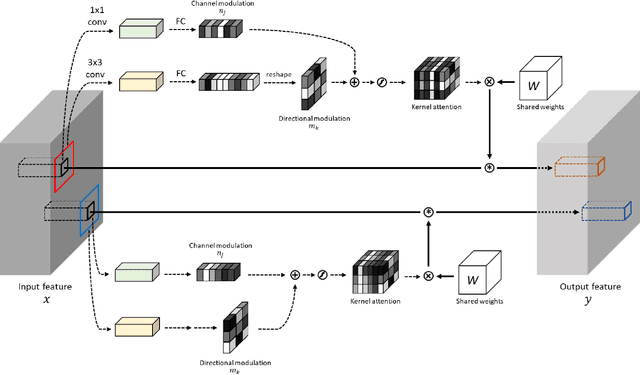
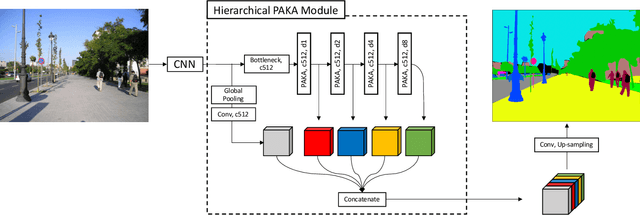
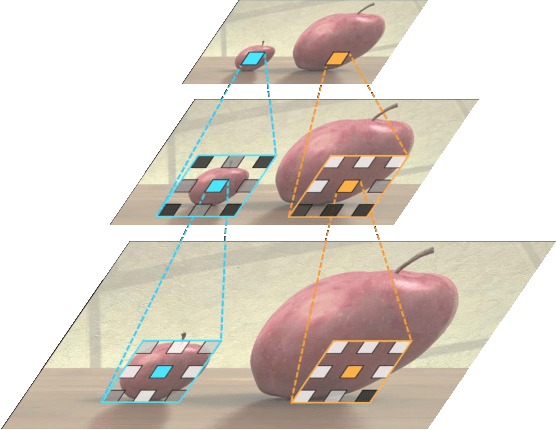
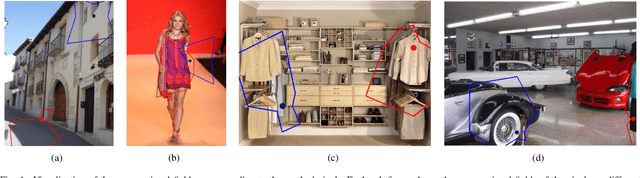
Convolutional neural networks (CNNs) have been not only widespread but also achieved noticeable results on numerous applications including image classification, restoration, and generation. Although the weight-sharing property of convolutions makes them widely adopted in various tasks, its content-agnostic characteristic can also be considered a major drawback. To solve this problem, in this paper, we propose a novel operation, called pixel adaptive kernel attention (PAKA). PAKA provides directivity to the filter weights by multiplying spatially varying attention from learnable features. The proposed method infers pixel-adaptive attention maps along the channel and spatial directions separately to address the decomposed model with fewer parameters. Our method is trainable in an end-to-end manner and applicable to any CNN-based models. In addition, we propose an improved information aggregation module with PAKA, called the hierarchical PAKA module (HPM). We demonstrate the superiority of our HPM by presenting state-of-the-art performance on semantic segmentation compared to the conventional information aggregation modules. We validate the proposed method through additional ablation studies and visualizing the effect of PAKA providing directivity to the weights of convolutions. We also show the generalizability of the proposed method by applying it to multi-modal tasks especially color-guided depth map super-resolution.
Generative Adversarial Network using Perturbed-Convolutions
Feb 02, 2021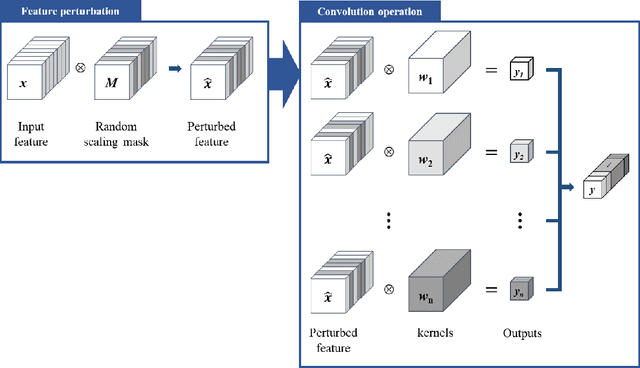
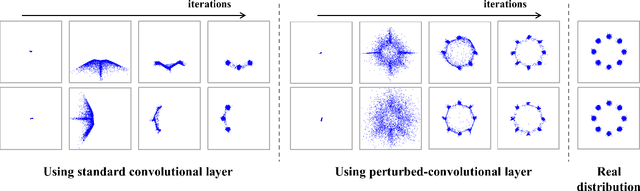

Despite growing insights into the GAN training, it still suffers from instability during the training procedure. To alleviate this problem, this paper presents a novel convolutional layer, called perturbed-convolution (PConv), which focuses on achieving two goals simultaneously: penalize the discriminator for training GAN stably and prevent the overfitting problem in the discriminator. PConv generates perturbed features by randomly disturbing an input tensor before performing the convolution operation. This approach is simple but surprisingly effective. First, to reliably classify real and generated samples using the disturbed input tensor, the intermediate layers in the discriminator should learn features having a small local Lipschitz value. Second, due to the perturbed features in PConv, the discriminator is difficult to memorize the real images; this makes the discriminator avoid the overfitting problem. To show the generalization ability of the proposed method, we conducted extensive experiments with various loss functions and datasets including CIFAR-10, CelebA-HQ, LSUN, and tiny-ImageNet. Quantitative evaluations demonstrate that WCL significantly improves the performance of GAN and conditional GAN in terms of Frechet inception distance (FID). For instance, the proposed method improves FID scores on the tiny-ImageNet dataset from 58.59 to 50.42.
A Simple yet Effective Way for Improving the Performance of GANs
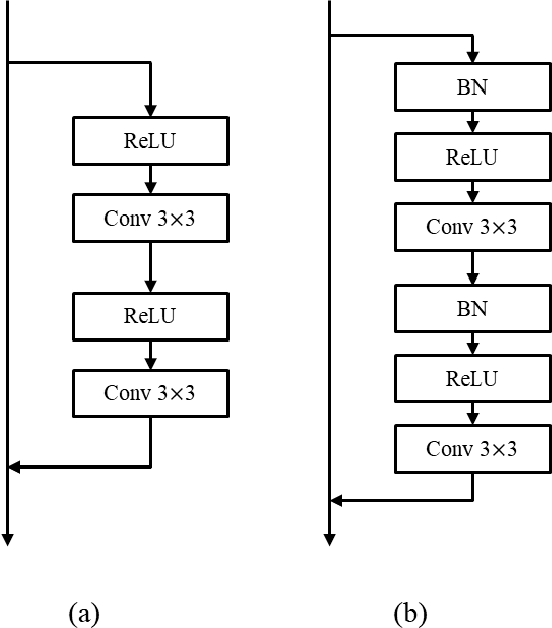
Dec 11, 2019

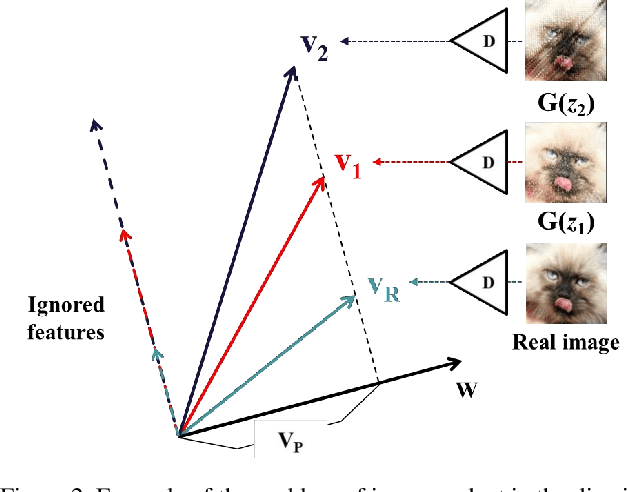

This paper presents a simple but effective way that improves the performance of generative adversarial networks (GANs) without imposing the training overhead or modifying the network architectures of existing methods. The proposed method employs a novel cascading rejection (CR) module for discriminator, which extracts multiple non-overlapped features in an iterative manner. The CR module supports the discriminator to effectively distinguish between real and generated images, which results in a strong penalization to the generator. In order to deceive the robust discriminator containing the CR module, the generator produces the images that are more similar to the real images. Since the proposed CR module requires only a few simple vector operations, it can be readily applied to existing frameworks with marginal training overheads. Quantitative evaluations on various datasets including CIFAR-10, Celeb-HQ, LSUN, and tiny-ImageNet confirm that the proposed method significantly improves the performance of GANs and conditional GANs in terms of Frechet inception distance (FID) indicating the diversity and visual appearance of the generated images.
cGANs with Conditional Convolution Layer
Jun 03, 2019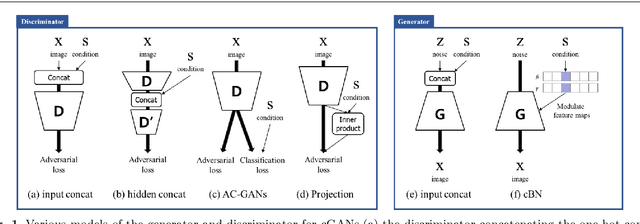

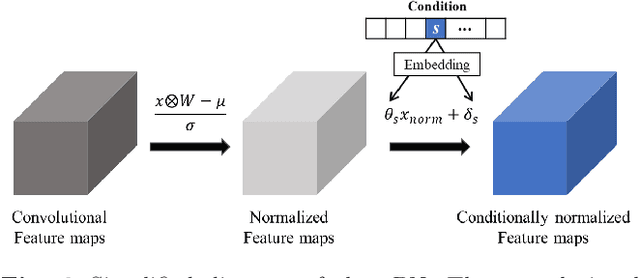

Conditional generative adversarial networks (cGANs) have been widely researched to generate class conditional images using a single generator. However, in the conventional cGANs techniques, it is still challenging for the generator to learn condition-specific features, since a standard convolutional layer with the same weights is used regardless of the condition. In this paper, we propose a novel convolution layer, called the conditional convolution layer, which directly generates different feature maps by employing the weights which are adjusted depending on the conditions. More specifically, in each conditional convolution layer, the weights are conditioned in a simple but effective way through filter-wise scaling and channel-wise shifting operations. In contrast to the conventional methods, the proposed method with a single generator can effectively handle condition-specific characteristics. The experimental results on CIFAR, LSUN and ImageNet datasets show that the generator with the proposed conditional convolution layer achieves a higher quality of conditional image generation than that with the standard convolution layer.
PEPSI++: Fast and Lightweight Network for Image Inpainting
May 22, 2019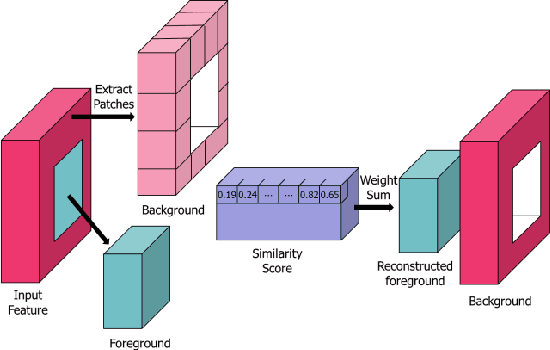
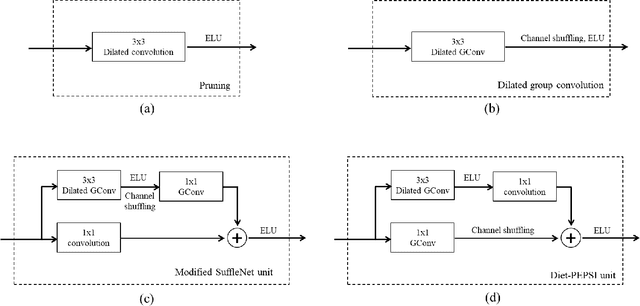


Generative adversarial network (GAN)-based image inpainting methods which utilize coarse-to-fine network with a contextual attention module (CAM) have shown remarkable performance. However, they require numerous computational resources such as convolution operations and network parameters due to two stacked generative networks, which results in a low speed. To address this problem, we propose a novel network structure called PEPSI: parallel extended-decoder path for semantic inpainting network, which aims at not only reducing hardware costs but also improving the inpainting performance. The PEPSI consists of a single shared encoding network and parallel decoding networks with coarse and inpainting paths. The coarse path generates a preliminary inpainting result to train the encoding network for prediction of features for the CAM. At the same time, the inpainting path results in higher inpainting quality with refined features reconstructed using the CAM. In addition, we propose a Diet-PEPSI which significantly reduces the network parameters while maintaining the performance. In the proposed method, we present a Diet-PEPSI unit (DPU) which effectively aggregates the global contextual information with a small number of parameters. Extensive experiments and comparisons with state-of-the-art image inpainting methods demonstrate that both PEPSI and Diet-PEPSI achieve significant improvements in qualitative scores and reduced computation cost.