 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSPGD: Rethinking Black-box Attacks on Semantic Segmentation
Feb 03, 2025Transferability, the ability of adversarial examples crafted for one model to deceive other models, is crucial for black-box attacks. Despite advancements in attack methods for semantic segmentation, transferability remains limited, reducing their effectiveness in real-world applications. To address this, we introduce the Feature Similarity Projected Gradient Descent (FSPGD) attack, a novel black-box approach that enhances both attack performance and transferability. Unlike conventional segmentation attacks that rely on output predictions for gradient calculation, FSPGD computes gradients from intermediate layer features. Specifically, our method introduces a loss function that targets local information by comparing features between clean images and adversarial examples, while also disrupting contextual information by accounting for spatial relationships between objects. Experiments on Pascal VOC 2012 and Cityscapes datasets demonstrate that FSPGD achieves superior transferability and attack performance, establishing a new state-of-the-art benchmark. Code is available at https://github.com/KU-AIVS/FSPGD.
Rethinking Image Skip Connections in StyleGAN2
Jul 08, 2024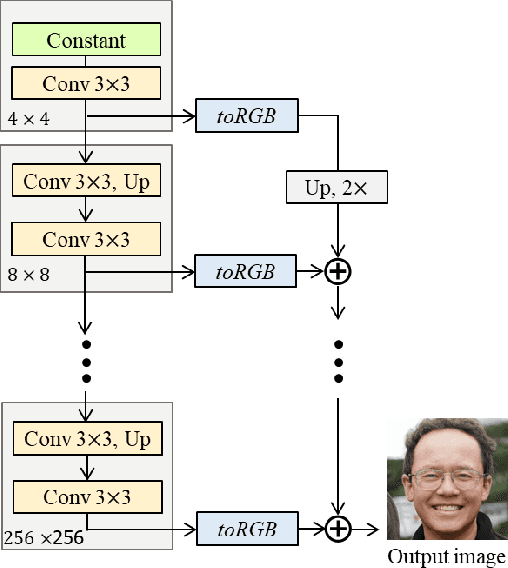
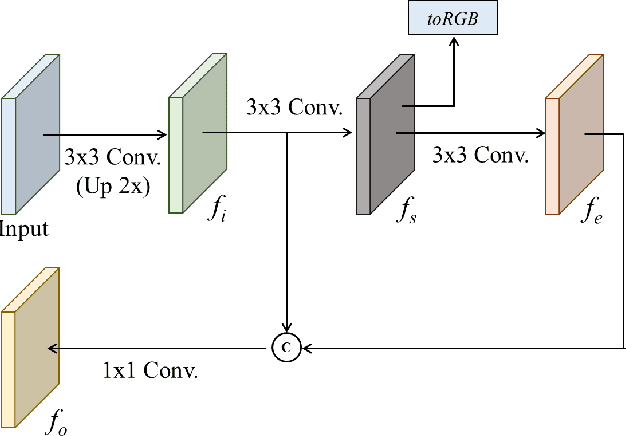


Various models based on StyleGAN have gained significant traction in the field of image synthesis, attributed to their robust training stability and superior performances. Within the StyleGAN framework, the adoption of image skip connection is favored over the traditional residual connection. However, this preference is just based on empirical observations; there has not been any in-depth mathematical analysis on it yet. To rectify this situation, this brief aims to elucidate the mathematical meaning of the image skip connection and introduce a groundbreaking methodology, termed the image squeeze connection, which significantly improves the quality of image synthesis. Specifically, we analyze the image skip connection technique to reveal its problem and introduce the proposed method which not only effectively boosts the GAN performance but also reduces the required number of network parameters. Extensive experiments on various datasets demonstrate that the proposed method consistently enhances the performance of state-of-the-art models based on StyleGAN. We believe that our findings represent a vital advancement in the field of image synthesis, suggesting a novel direction for future research and applications.
IF-GAN: A Novel Generator Architecture with Information Feedback
Oct 18, 2022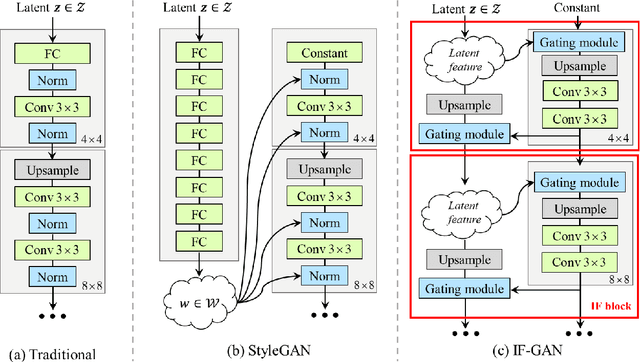
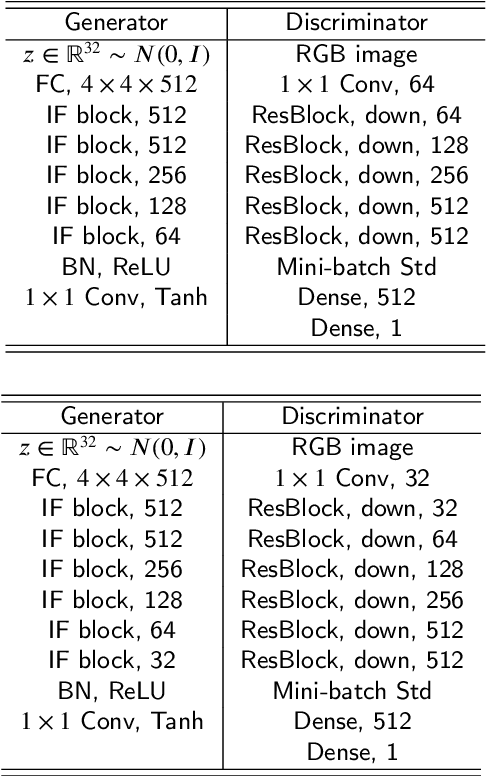
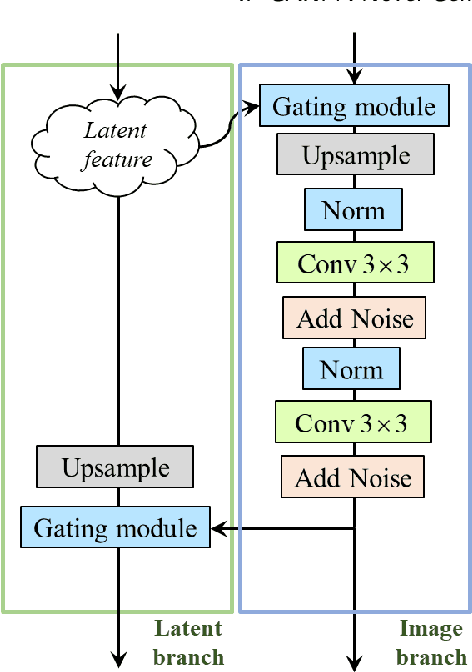
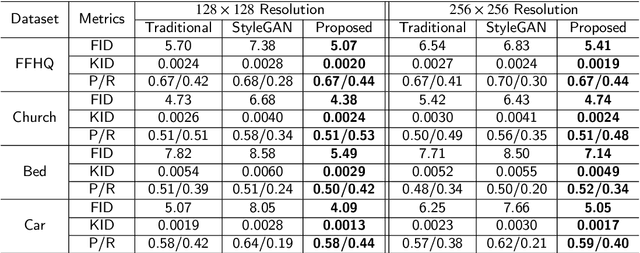
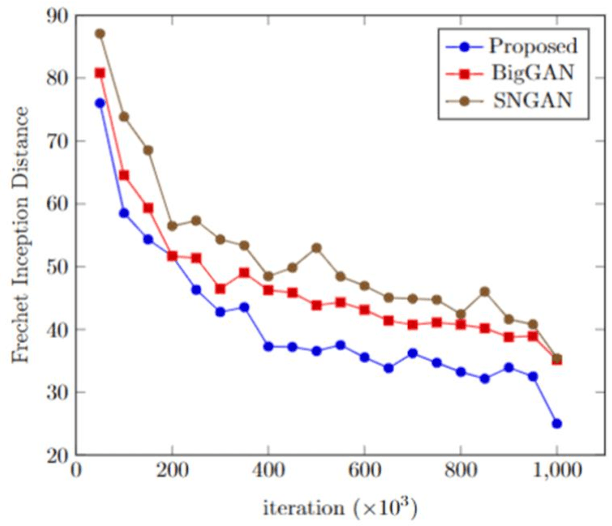
This paper presents an alternative generator architecture for image generation, having a novel information feedback system. Contrary to conventional methods in which the latent space unilaterally affects the feature space in the generator, the proposed method trains not only the feature space but also the latent one by interchanging their information. To this end, we introduce a novel module, called information feedback (IF) block, which jointly updates the latent and feature spaces. To show the superiority of the proposed method, we present extensive experiments on various datasets including subsets of LSUN and FFHQ. Experimental results reveal that the proposed method can dramatically improve the image generation performance, in terms of Frechet inception distance (FID), kernel inception distance (KID), and Precision and Recall (P & R).
Effective Shortcut Technique for GAN
Jan 27, 2022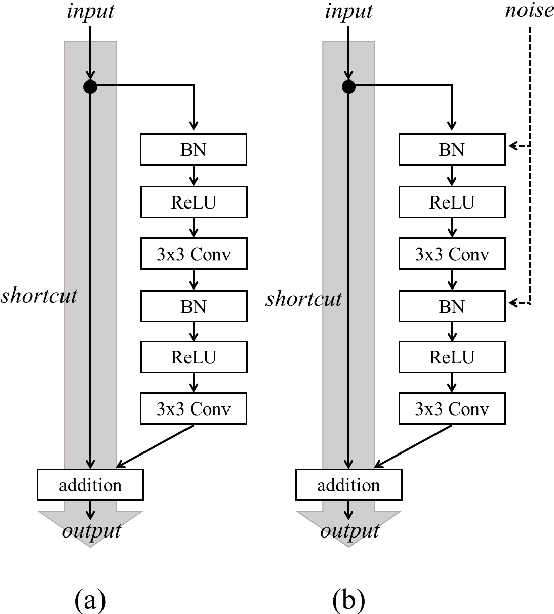
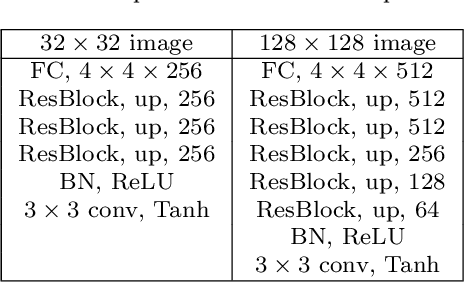
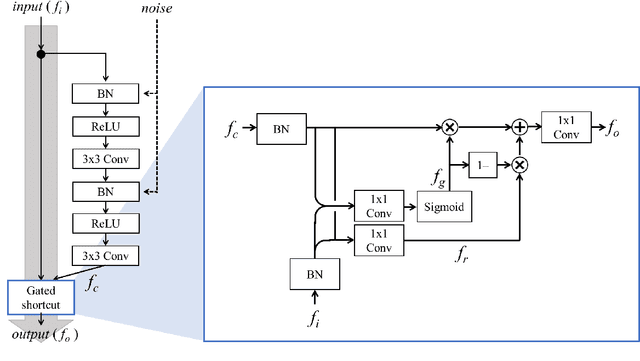
In recent years, generative adversarial network (GAN)-based image generation techniques design their generators by stacking up multiple residual blocks. The residual block generally contains a shortcut, \ie skip connection, which effectively supports information propagation in the network. In this paper, we propose a novel shortcut method, called the gated shortcut, which not only embraces the strength point of the residual block but also further boosts the GAN performance. More specifically, based on the gating mechanism, the proposed method leads the residual block to keep (or remove) information that is relevant (or irrelevant) to the image being generated. To demonstrate that the proposed method brings significant improvements in the GAN performance, this paper provides extensive experimental results on the various standard datasets such as CIFAR-10, CIFAR-100, LSUN, and tiny-ImageNet. Quantitative evaluations show that the gated shortcut achieves the impressive GAN performance in terms of Frechet inception distance (FID) and Inception score (IS). For instance, the proposed method improves the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 27.90 and 20.23 to 23.42, respectively.
Image Generation with Self Pixel-wise Normalization
Jan 26, 2022Region-adaptive normalization (RAN) methods have been widely used in the generative adversarial network (GAN)-based image-to-image translation technique. However, since these approaches need a mask image to infer the pixel-wise affine transformation parameters, they cannot be applied to the general image generation models having no paired mask images. To resolve this problem, this paper presents a novel normalization method, called self pixel-wise normalization (SPN), which effectively boosts the generative performance by performing the pixel-adaptive affine transformation without the mask image. In our method, the transforming parameters are derived from a self-latent mask that divides the feature map into the foreground and background regions. The visualization of the self-latent masks shows that SPN effectively captures a single object to be generated as the foreground. Since the proposed method produces the self-latent mask without external data, it is easily applicable in the existing generative models. Extensive experiments on various datasets reveal that the proposed method significantly improves the performance of image generation technique in terms of Frechet inception distance (FID) and Inception score (IS).
A Novel Generator with Auxiliary Branch for Improving GAN Performance
Dec 30, 2021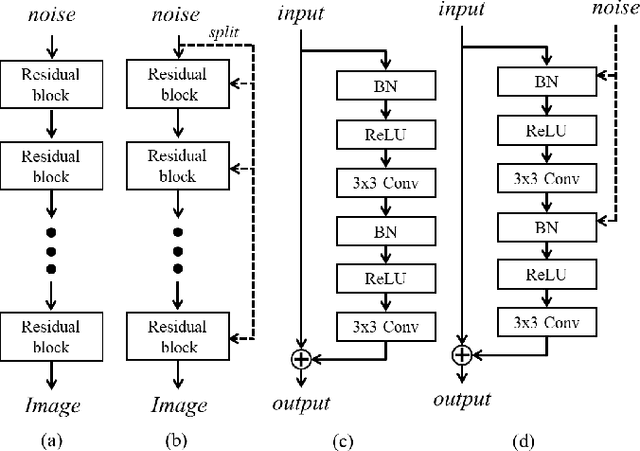
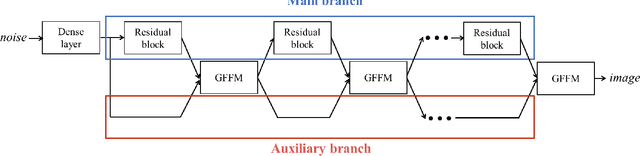
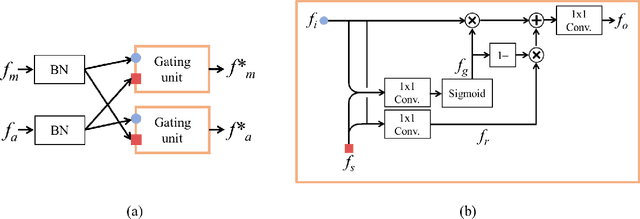
The generator in the generative adversarial network (GAN) learns image generation in a coarse-to-fine manner in which earlier layers learn an overall structure of the image and the latter ones refine the details. To propagate the coarse information well, recent works usually build their generators by stacking up multiple residual blocks. Although the residual block can produce the high-quality image as well as be trained stably, it often impedes the information flow in the network. To alleviate this problem, this brief introduces a novel generator architecture that produces the image by combining features obtained through two different branches: the main and auxiliary branches. The goal of the main branch is to produce the image by passing through the multiple residual blocks, whereas the auxiliary branch is to convey the coarse information in the earlier layer to the later one. To combine the features in the main and auxiliary branches successfully, we also propose a gated feature fusion module that controls the information flow in those branches. To prove the superiority of the proposed method, this brief provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN, CelebA-HQ, AFHQ, and tiny- ImageNet. Furthermore, we conducted various ablation studies to demonstrate the generalization ability of the proposed method. Quantitative evaluations prove that the proposed method exhibits impressive GAN performance in terms of Inception score (IS) and Frechet inception distance (FID). For instance, the proposed method boosts the FID and IS scores on the tiny-ImageNet dataset from 35.13 to 25.00 and 20.23 to 25.57, respectively.
Generative Convolution Layer for Image Generation
Nov 30, 2021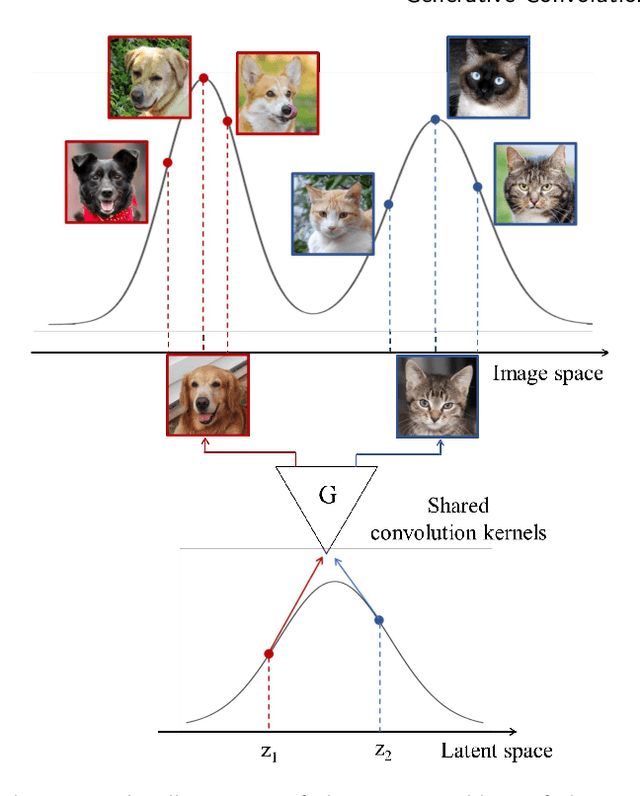
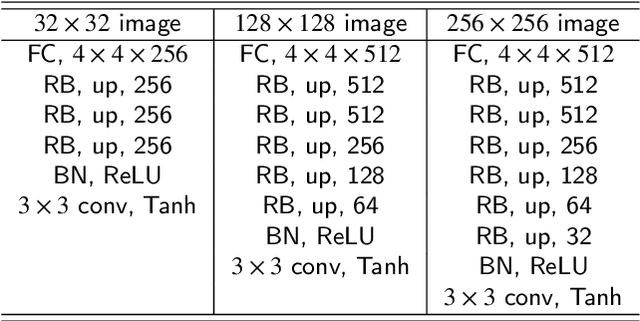
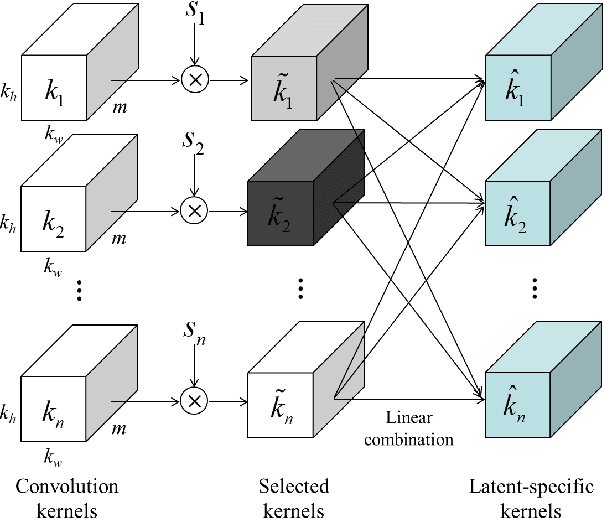
This paper introduces a novel convolution method, called generative convolution (GConv), which is simple yet effective for improving the generative adversarial network (GAN) performance. Unlike the standard convolution, GConv first selects useful kernels compatible with the given latent vector, and then linearly combines the selected kernels to make latent-specific kernels. Using the latent-specific kernels, the proposed method produces the latent-specific features which encourage the generator to produce high-quality images. This approach is simple but surprisingly effective. First, the GAN performance is significantly improved with a little additional hardware cost. Second, GConv can be employed to the existing state-of-the-art generators without modifying the network architecture. To reveal the superiority of GConv, this paper provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN-Church, CelebA, and tiny-ImageNet. Quantitative evaluations prove that GConv significantly boosts the performances of the unconditional and conditional GANs in terms of Inception score (IS) and Frechet inception distance (FID). For example, the proposed method improves both FID and IS scores on the tiny-ImageNet dataset from 35.13 to 29.76 and 20.23 to 22.64, respectively.
Generative Adversarial Network using Perturbed-Convolutions
Feb 02, 2021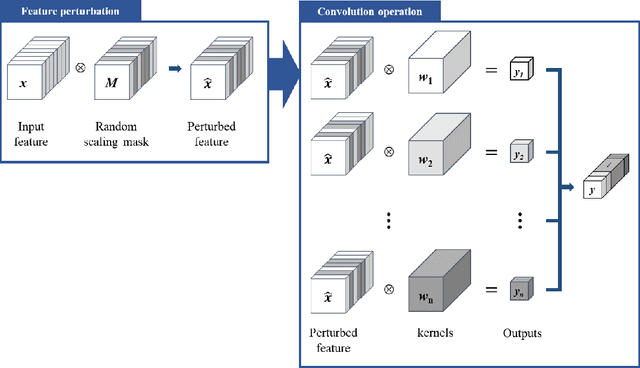
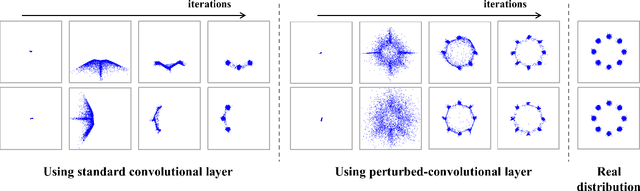

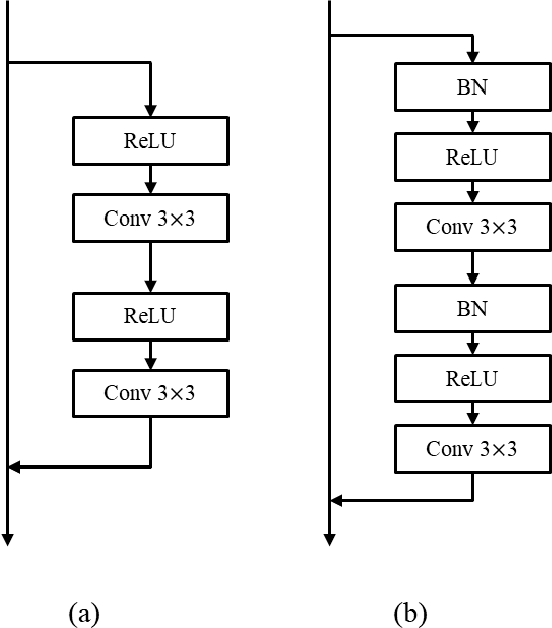
Despite growing insights into the GAN training, it still suffers from instability during the training procedure. To alleviate this problem, this paper presents a novel convolutional layer, called perturbed-convolution (PConv), which focuses on achieving two goals simultaneously: penalize the discriminator for training GAN stably and prevent the overfitting problem in the discriminator. PConv generates perturbed features by randomly disturbing an input tensor before performing the convolution operation. This approach is simple but surprisingly effective. First, to reliably classify real and generated samples using the disturbed input tensor, the intermediate layers in the discriminator should learn features having a small local Lipschitz value. Second, due to the perturbed features in PConv, the discriminator is difficult to memorize the real images; this makes the discriminator avoid the overfitting problem. To show the generalization ability of the proposed method, we conducted extensive experiments with various loss functions and datasets including CIFAR-10, CelebA-HQ, LSUN, and tiny-ImageNet. Quantitative evaluations demonstrate that WCL significantly improves the performance of GAN and conditional GAN in terms of Frechet inception distance (FID). For instance, the proposed method improves FID scores on the tiny-ImageNet dataset from 58.59 to 50.42.
cGANs with Conditional Convolution Layer
Jun 03, 2019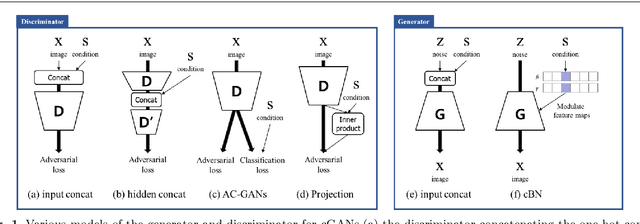

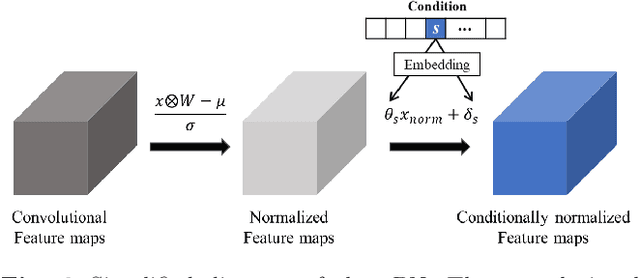

Conditional generative adversarial networks (cGANs) have been widely researched to generate class conditional images using a single generator. However, in the conventional cGANs techniques, it is still challenging for the generator to learn condition-specific features, since a standard convolutional layer with the same weights is used regardless of the condition. In this paper, we propose a novel convolution layer, called the conditional convolution layer, which directly generates different feature maps by employing the weights which are adjusted depending on the conditions. More specifically, in each conditional convolution layer, the weights are conditioned in a simple but effective way through filter-wise scaling and channel-wise shifting operations. In contrast to the conventional methods, the proposed method with a single generator can effectively handle condition-specific characteristics. The experimental results on CIFAR, LSUN and ImageNet datasets show that the generator with the proposed conditional convolution layer achieves a higher quality of conditional image generation than that with the standard convolution layer.
Unsupervised Deep Power Saving and Contrast Enhancement for OLED Displays
May 15, 2019

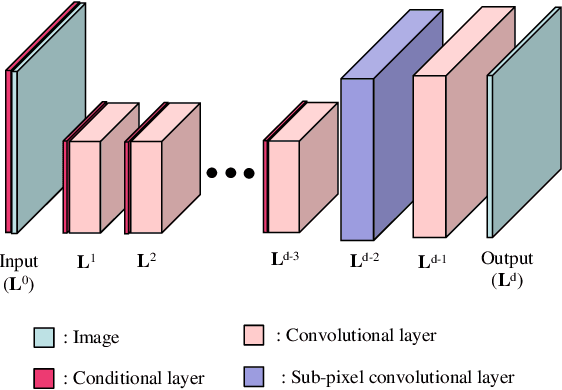

Various power saving and contrast enhancement (PSCE) techniques have been applied to an organic light emitting diode (OLED) display for reducing the power demands of the display while preserving the image quality. In this paper, we propose a new deep learning-based PSCE scheme that can save power consumed by the OLED display while enhancing the contrast of the displayed image. In the proposed method, the power consumption is saved by simply reducing the brightness a certain ratio, whereas the perceived visual quality is preserved as much as possible by enhancing the contrast of the image using a convolutional neural network (CNN). Furthermore, our CNN can learn the PSCE technique without a reference image by unsupervised learning. Experimental results show that the proposed method is superior to conventional ones in terms of image quality assessment metrics such as a visual saliency-induced index (VSI) and a measure of enhancement (EME).