 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-aware Directed Propagation Network with Pixel Adaptive Kernel Attention
Paper and Code
Jul 28, 2021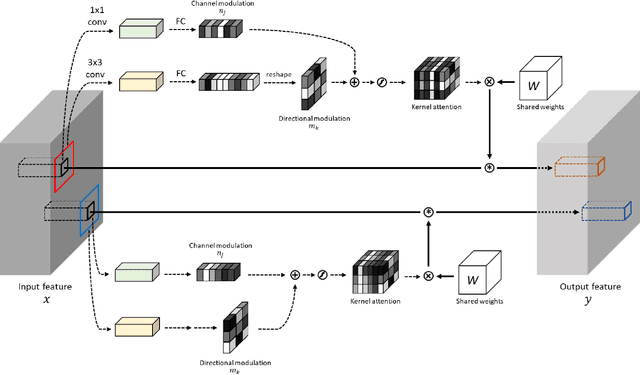
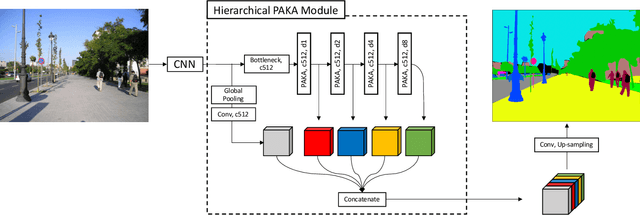
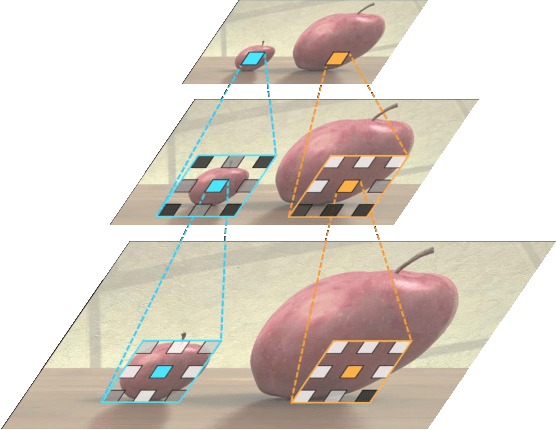
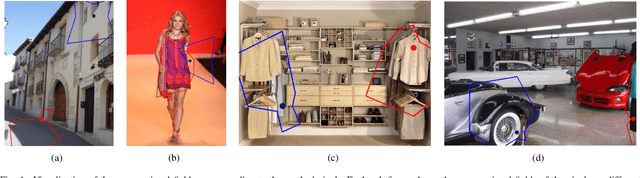
Convolutional neural networks (CNNs) have been not only widespread but also achieved noticeable results on numerous applications including image classification, restoration, and generation. Although the weight-sharing property of convolutions makes them widely adopted in various tasks, its content-agnostic characteristic can also be considered a major drawback. To solve this problem, in this paper, we propose a novel operation, called pixel adaptive kernel attention (PAKA). PAKA provides directivity to the filter weights by multiplying spatially varying attention from learnable features. The proposed method infers pixel-adaptive attention maps along the channel and spatial directions separately to address the decomposed model with fewer parameters. Our method is trainable in an end-to-end manner and applicable to any CNN-based models. In addition, we propose an improved information aggregation module with PAKA, called the hierarchical PAKA module (HPM). We demonstrate the superiority of our HPM by presenting state-of-the-art performance on semantic segmentation compared to the conventional information aggregation modules. We validate the proposed method through additional ablation studies and visualizing the effect of PAKA providing directivity to the weights of convolutions. We also show the generalizability of the proposed method by applying it to multi-modal tasks especially color-guided depth map super-resolution.