 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefQSR: Reference-based Quantization for Image Super-Resolution Networks
Apr 02, 2024Single image super-resolution (SISR) aims to reconstruct a high-resolution image from its low-resolution observation. Recent deep learning-based SISR models show high performance at the expense of increased computational costs, limiting their use in resource-constrained environments. As a promising solution for computationally efficient network design, network quantization has been extensively studied. However, existing quantization methods developed for SISR have yet to effectively exploit image self-similarity, which is a new direction for exploration in this study. We introduce a novel method called reference-based quantization for image super-resolution (RefQSR) that applies high-bit quantization to several representative patches and uses them as references for low-bit quantization of the rest of the patches in an image. To this end, we design dedicated patch clustering and reference-based quantization modules and integrate them into existing SISR network quantization methods. The experimental results demonstrate the effectiveness of RefQSR on various SISR networks and quantization methods.
Hierarchical Spatiotemporal Transformers for Video Object Segmentation
Jul 17, 2023



This paper presents a novel framework called HST for semi-supervised video object segmentation (VOS). HST extracts image and video features using the latest Swin Transformer and Video Swin Transformer to inherit their inductive bias for the spatiotemporal locality, which is essential for temporally coherent VOS. To take full advantage of the image and video features, HST casts image and video features as a query and memory, respectively. By applying efficient memory read operations at multiple scales, HST produces hierarchical features for the precise reconstruction of object masks. HST shows effectiveness and robustness in handling challenging scenarios with occluded and fast-moving objects under cluttered backgrounds. In particular, HST-B outperforms the state-of-the-art competitors on multiple popular benchmarks, i.e., YouTube-VOS (85.0%), DAVIS 2017 (85.9%), and DAVIS 2016 (94.0%).
RZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Aug 24, 2022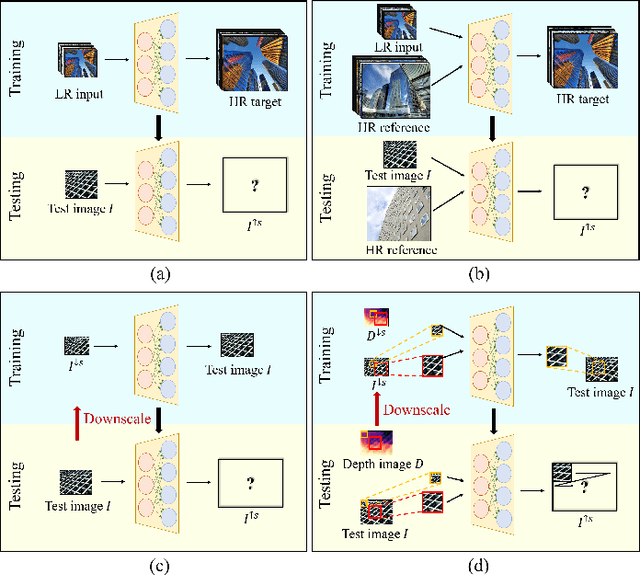
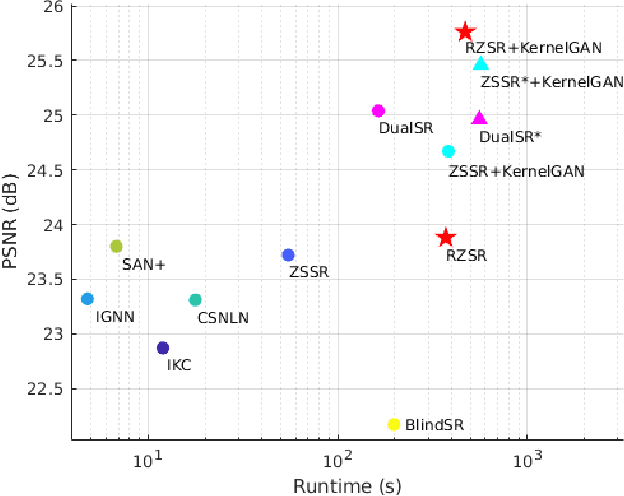
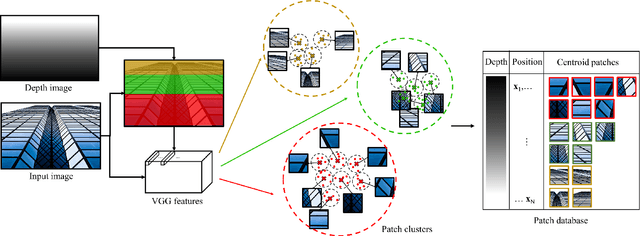
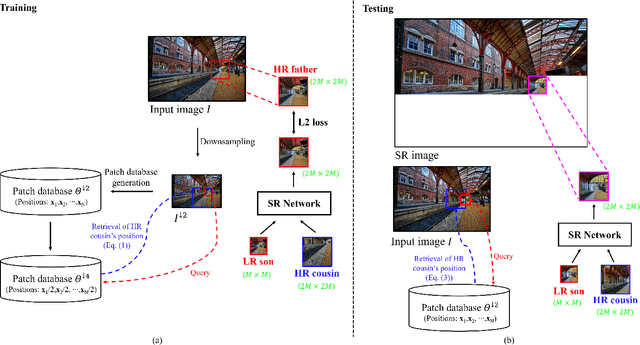
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.