 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRZSR: Reference-based Zero-Shot Super-Resolution with Depth Guided Self-Exemplars
Paper and Code
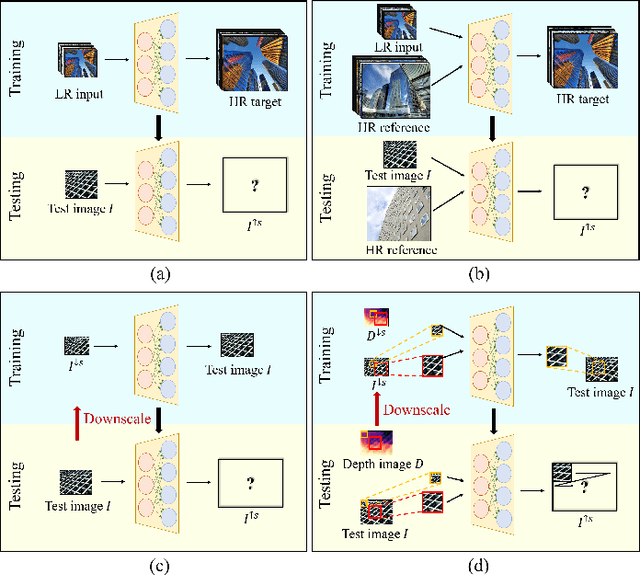
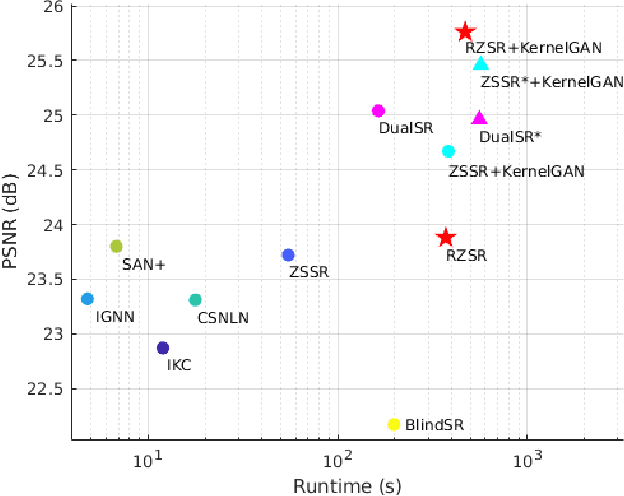
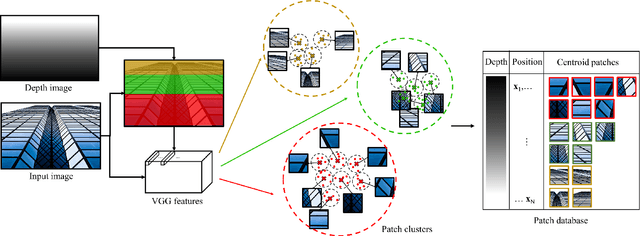
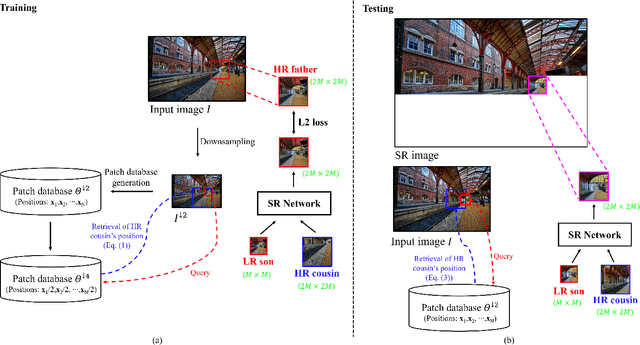
Recent methods for single image super-resolution (SISR) have demonstrated outstanding performance in generating high-resolution (HR) images from low-resolution (LR) images. However, most of these methods show their superiority using synthetically generated LR images, and their generalizability to real-world images is often not satisfactory. In this paper, we pay attention to two well-known strategies developed for robust super-resolution (SR), i.e., reference-based SR (RefSR) and zero-shot SR (ZSSR), and propose an integrated solution, called reference-based zero-shot SR (RZSR). Following the principle of ZSSR, we train an image-specific SR network at test time using training samples extracted only from the input image itself. To advance ZSSR, we obtain reference image patches with rich textures and high-frequency details which are also extracted only from the input image using cross-scale matching. To this end, we construct an internal reference dataset and retrieve reference image patches from the dataset using depth information. Using LR patches and their corresponding HR reference patches, we train a RefSR network that is embodied with a non-local attention module. Experimental results demonstrate the superiority of the proposed RZSR compared to the previous ZSSR methods and robustness to unseen images compared to other fully supervised SISR methods.