 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanX: Toward Agile and Generalizable Humanoid Interaction Skills from Human Videos
Feb 02, 2026Enabling humanoid robots to perform agile and adaptive interactive tasks has long been a core challenge in robotics. Current approaches are bottlenecked by either the scarcity of realistic interaction data or the need for meticulous, task-specific reward engineering, which limits their scalability. To narrow this gap, we present HumanX, a full-stack framework that compiles human video into generalizable, real-world interaction skills for humanoids, without task-specific rewards. HumanX integrates two co-designed components: XGen, a data generation pipeline that synthesizes diverse and physically plausible robot interaction data from video while supporting scalable data augmentation; and XMimic, a unified imitation learning framework that learns generalizable interaction skills. Evaluated across five distinct domains--basketball, football, badminton, cargo pickup, and reactive fighting--HumanX successfully acquires 10 different skills and transfers them zero-shot to a physical Unitree G1 humanoid. The learned capabilities include complex maneuvers such as pump-fake turnaround fadeaway jumpshots without any external perception, as well as interactive tasks like sustained human-robot passing sequences over 10 consecutive cycles--learned from a single video demonstration. Our experiments show that HumanX achieves over 8 times higher generalization success than prior methods, demonstrating a scalable and task-agnostic pathway for learning versatile, real-world robot interactive skills.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
SkillMimic-V2: Learning Robust and Generalizable Interaction Skills from Sparse and Noisy Demonstrations
May 04, 2025We address a fundamental challenge in Reinforcement Learning from Interaction Demonstration (RLID): demonstration noise and coverage limitations. While existing data collection approaches provide valuable interaction demonstrations, they often yield sparse, disconnected, and noisy trajectories that fail to capture the full spectrum of possible skill variations and transitions. Our key insight is that despite noisy and sparse demonstrations, there exist infinite physically feasible trajectories that naturally bridge between demonstrated skills or emerge from their neighboring states, forming a continuous space of possible skill variations and transitions. Building upon this insight, we present two data augmentation techniques: a Stitched Trajectory Graph (STG) that discovers potential transitions between demonstration skills, and a State Transition Field (STF) that establishes unique connections for arbitrary states within the demonstration neighborhood. To enable effective RLID with augmented data, we develop an Adaptive Trajectory Sampling (ATS) strategy for dynamic curriculum generation and a historical encoding mechanism for memory-dependent skill learning. Our approach enables robust skill acquisition that significantly generalizes beyond the reference demonstrations. Extensive experiments across diverse interaction tasks demonstrate substantial improvements over state-of-the-art methods in terms of convergence stability, generalization capability, and recovery robustness.
Enlighten Anything: When Segment Anything Model Meets Low-Light Image Enhancement
Jun 22, 2023
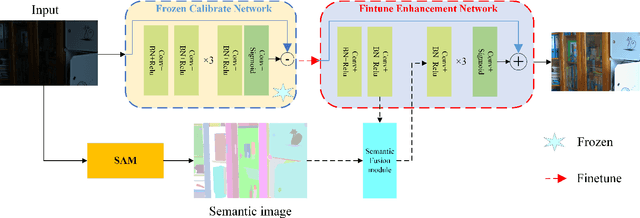


Image restoration is a low-level visual task, and most CNN methods are designed as black boxes, lacking transparency and intrinsic aesthetics. Many unsupervised approaches ignore the degradation of visible information in low-light scenes, which will seriously affect the aggregation of complementary information and also make the fusion algorithm unable to produce satisfactory fusion results under extreme conditions. In this paper, we propose Enlighten-anything, which is able to enhance and fuse the semantic intent of SAM segmentation with low-light images to obtain fused images with good visual perception. The generalization ability of unsupervised learning is greatly improved, and experiments on LOL dataset are conducted to show that our method improves 3db in PSNR over baseline and 8 in SSIM. Zero-shot learning of SAM introduces a powerful aid for unsupervised low-light enhancement. The source code of Enlighten Anything can be obtained from https://github.com/zhangbaijin/enlighten-anything