 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernelDNA: Dynamic Kernel Sharing via Decoupled Naive Adapters
Paper and Code
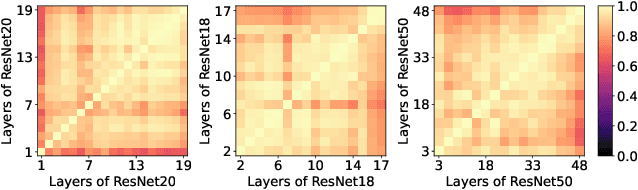
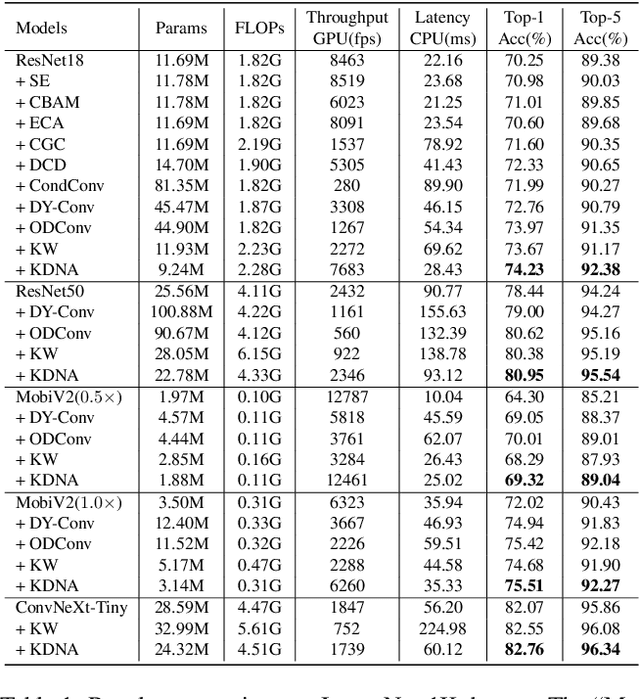
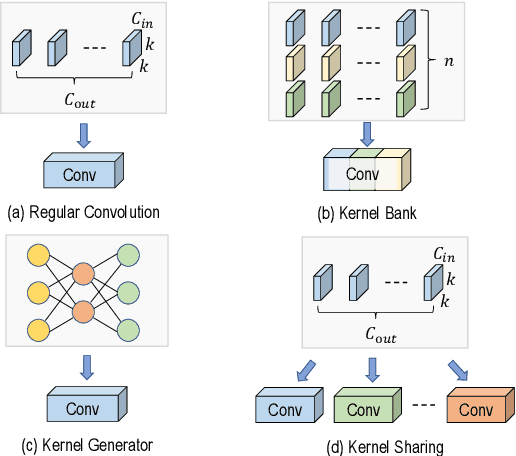
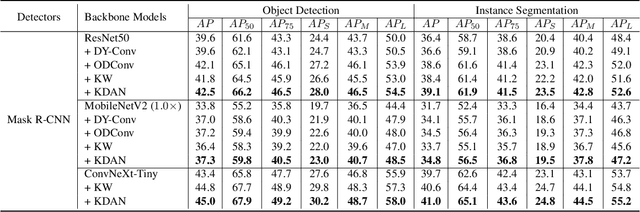
Dynamic convolution enhances model capacity by adaptively combining multiple kernels, yet faces critical trade-offs: prior works either (1) incur significant parameter overhead by scaling kernel numbers linearly, (2) compromise inference speed through complex kernel interactions, or (3) struggle to jointly optimize dynamic attention and static kernels. We also observe that pre-trained Convolutional Neural Networks (CNNs) exhibit inter-layer redundancy akin to that in Large Language Models (LLMs). Specifically, dense convolutional layers can be efficiently replaced by derived ``child" layers generated from a shared ``parent" convolutional kernel through an adapter. To address these limitations and implement the weight-sharing mechanism, we propose a lightweight convolution kernel plug-in, named KernelDNA. It decouples kernel adaptation into input-dependent dynamic routing and pre-trained static modulation, ensuring both parameter efficiency and hardware-friendly inference. Unlike existing dynamic convolutions that expand parameters via multi-kernel ensembles, our method leverages cross-layer weight sharing and adapter-based modulation, enabling dynamic kernel specialization without altering the standard convolution structure. This design preserves the native computational efficiency of standard convolutions while enhancing representation power through input-adaptive kernel adjustments. Experiments on image classification and dense prediction tasks demonstrate that KernelDNA achieves state-of-the-art accuracy-efficiency balance among dynamic convolution variants. Our codes are available at https://github.com/haiduo/KernelDNA.