 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-time Endoscopic Image Denoising System
Jun 18, 2025
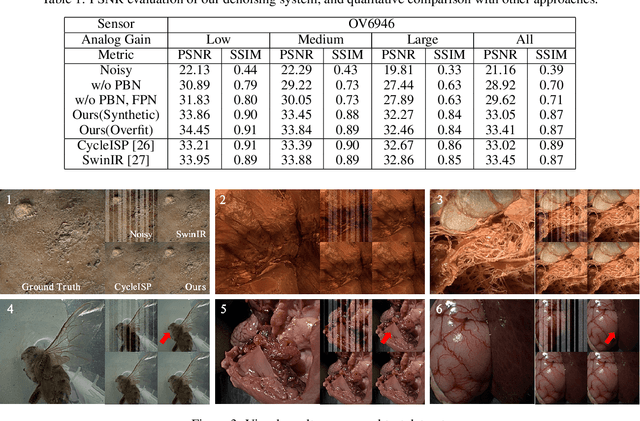

Endoscopes featuring a miniaturized design have significantly enhanced operational flexibility, portability, and diagnostic capability while substantially reducing the invasiveness of medical procedures. Recently, single-use endoscopes equipped with an ultra-compact analogue image sensor measuring less than 1mm x 1mm bring revolutionary advancements to medical diagnosis. They reduce the structural redundancy and large capital expenditures associated with reusable devices, eliminate the risk of patient infections caused by inadequate disinfection, and alleviate patient suffering. However, the limited photosensitive area results in reduced photon capture per pixel, requiring higher photon sensitivity settings to maintain adequate brightness. In high-contrast medical imaging scenarios, the small-sized sensor exhibits a constrained dynamic range, making it difficult to simultaneously capture details in both highlights and shadows, and additional localized digital gain is required to compensate. Moreover, the simplified circuit design and analog signal transmission introduce additional noise sources. These factors collectively contribute to significant noise issues in processed endoscopic images. In this work, we developed a comprehensive noise model for analog image sensors in medical endoscopes, addressing three primary noise types: fixed-pattern noise, periodic banding noise, and mixed Poisson-Gaussian noise. Building on this analysis, we propose a hybrid denoising system that synergistically combines traditional image processing algorithms with advanced learning-based techniques for captured raw frames from sensors. Experiments demonstrate that our approach effectively reduces image noise without fine detail loss or color distortion, while achieving real-time performance on FPGA platforms and an average PSNR improvement from 21.16 to 33.05 on our test dataset.
DNNVM : End-to-End Compiler Leveraging Heterogeneous Optimizations on FPGA-based CNN Accelerators
Feb 20, 2019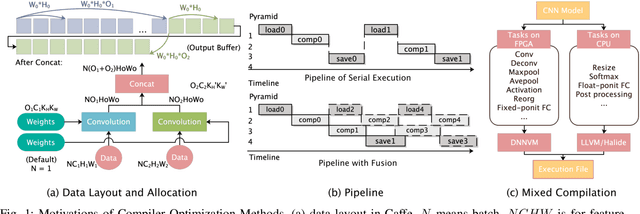

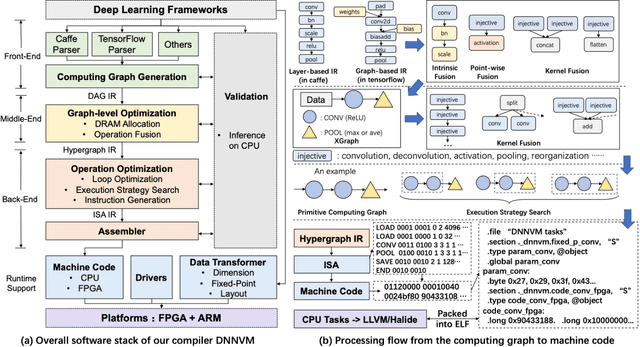
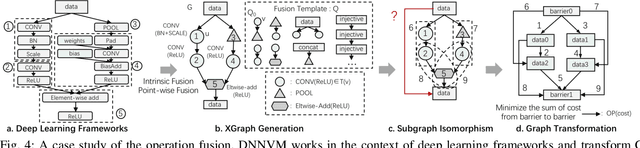
The convolutional neural network (CNN) has become a state-of-the-art method for several artificial intelligence domains in recent years. The increasingly complex CNN models are both computation-bound and I/O-bound. FPGA-based accelerators driven by custom instruction set architecture (ISA) achieve a balance between generality and efficiency, but there is much on them left to be optimized. We propose the full-stack compiler DNNVM, which is an integration of optimizers for graphs, loops and data layouts, and an assembler, a runtime supporter and a validation environment. The DNNVM works in the context of deep learning frameworks and transforms CNN models into the directed acyclic graph: XGraph. Based on XGraph, we transform the optimization challenges for both the data layout and pipeline into graph-level problems. DNNVM enumerates all potentially profitable fusion opportunities by a heuristic subgraph isomorphism algorithm to leverage pipeline and data layout optimizations, and searches for the optimal execution strategies of the whole computing graph. On the Xilinx ZU2 @330 MHz and ZU9 @330 MHz, we achieve equivalently state-of-the-art performance on our benchmarks by naive implementations without optimizations, and the throughput is further improved up to 1.26x by leveraging heterogeneous optimizations in DNNVM. Finally, with ZU9 @330 MHz, we achieve state-of-the-art performance for VGG and ResNet50. We achieve a throughput of 2.82 TOPs/s and an energy efficiency of 123.7 GOPs/s/W for VGG. Additionally, we achieve 1.38 TOPs/s for ResNet50.