 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Dataset Collaborative Learning for Semantic Segmentation
Paper and Code
Mar 21, 2021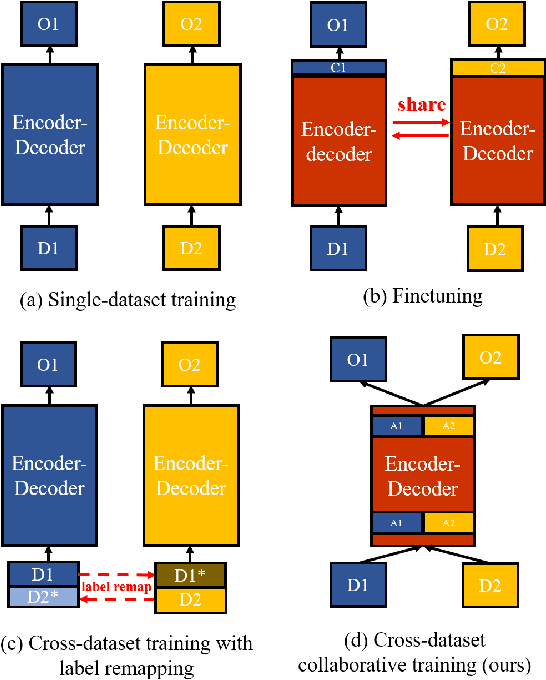
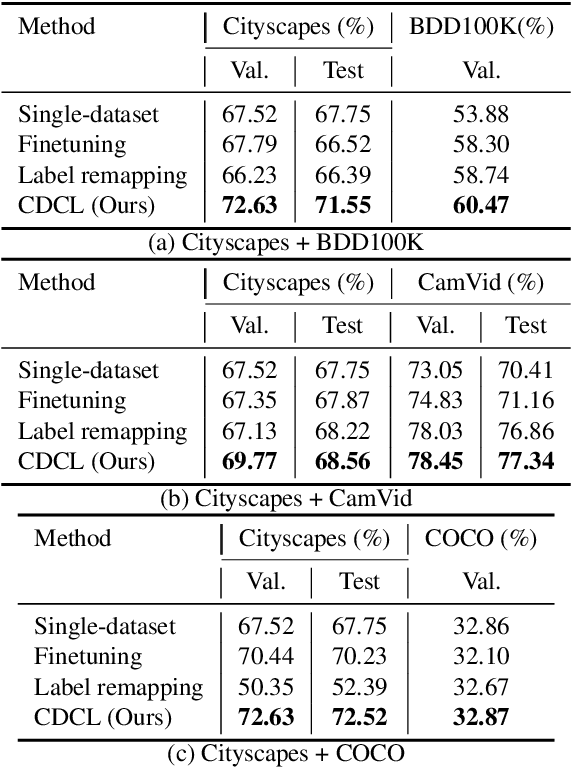
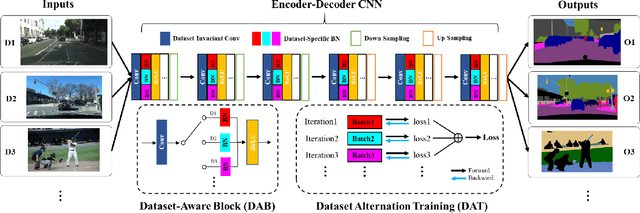

Recent work attempts to improve semantic segmentation performance by exploring well-designed architectures on a target dataset. However, it remains challenging to build a unified system that simultaneously learns from various datasets due to the inherent distribution shift across different datasets. In this paper, we present a simple, flexible, and general method for semantic segmentation, termed Cross-Dataset Collaborative Learning (CDCL). Given multiple labeled datasets, we aim to improve the generalization and discrimination of feature representations on each dataset. Specifically, we first introduce a family of Dataset-Aware Blocks (DAB) as the fundamental computing units of the network, which help capture homogeneous representations and heterogeneous statistics across different datasets. Second, we propose a Dataset Alternation Training (DAT) mechanism to efficiently facilitate the optimization procedure. We conduct extensive evaluations on four diverse datasets, i.e., Cityscapes, BDD100K, CamVid, and COCO Stuff, with single-dataset and cross-dataset settings. Experimental results demonstrate our method consistently achieves notable improvements over prior single-dataset and cross-dataset training methods without introducing extra FLOPs. Particularly, with the same architecture of PSPNet (ResNet-18), our method outperforms the single-dataset baseline by 5.65\%, 6.57\%, and 5.79\% of mIoU on the validation sets of Cityscapes, BDD100K, CamVid, respectively. Code and models will be released.