 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Image Descriptor with Aggregated Semantic Skeleton Representation for Long-term Visual Place Recognition
Feb 08, 2022


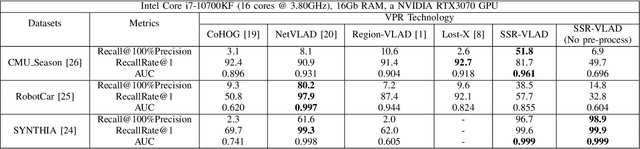
In a Simultaneous Localization and Mapping (SLAM) system, a loop-closure can eliminate accumulated errors, which is accomplished by Visual Place Recognition (VPR), a task that retrieves the current scene from a set of pre-stored sequential images through matching specific scene-descriptors. In urban scenes, the appearance variation caused by seasons and illumination has brought great challenges to the robustness of scene descriptors. Semantic segmentation images can not only deliver the shape information of objects but also their categories and spatial relations that will not be affected by the appearance variation of the scene. Innovated by the Vector of Locally Aggregated Descriptor (VLAD), in this paper, we propose a novel image descriptor with aggregated semantic skeleton representation (SSR), dubbed SSR-VLAD, for the VPR under drastic appearance-variation of environments. The SSR-VLAD of one image aggregates the semantic skeleton features of each category and encodes the spatial-temporal distribution information of the image semantic information. We conduct a series of experiments on three public datasets of challenging urban scenes. Compared with four state-of-the-art VPR methods- CoHOG, NetVLAD, LOST-X, and Region-VLAD, VPR by matching SSR-VLAD outperforms those methods and maintains competitive real-time performance at the same time.