 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Perplexity for Controlled Generation: An Application in Detoxifying Large Language Models
Paper and Code
Jan 24, 2024
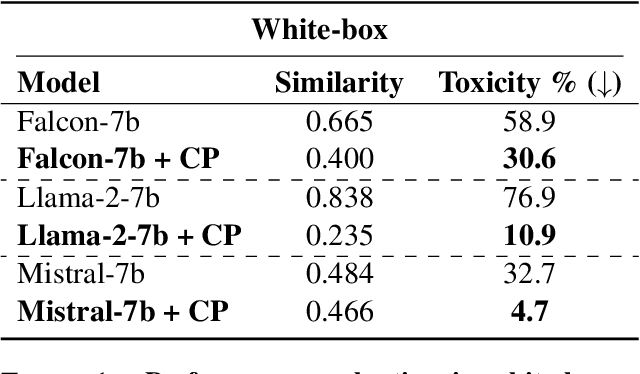


The generation of undesirable and factually incorrect content of large language models poses a significant challenge and remains largely an unsolved issue. This paper studies the integration of a contrastive learning objective for fine-tuning LLMs for implicit knowledge editing and controlled text generation. Optimizing the training objective entails aligning text perplexities in a contrastive fashion. To facilitate training the model in a self-supervised fashion, we leverage an off-the-shelf LLM for training data generation. We showcase applicability in the domain of detoxification. Herein, the proposed approach leads to a significant decrease in the generation of toxic content while preserving general utility for downstream tasks such as commonsense reasoning and reading comprehension. The proposed approach is conceptually simple but empirically powerful.