 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Procrustean Bed of Time Series: The Optimization Bias of Point-wise Loss
Dec 21, 2025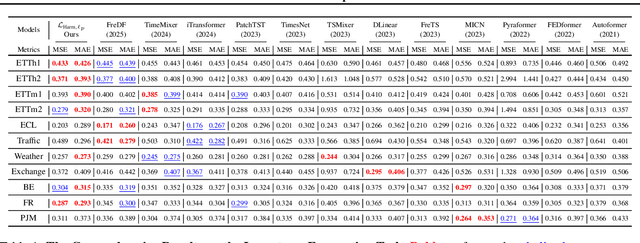
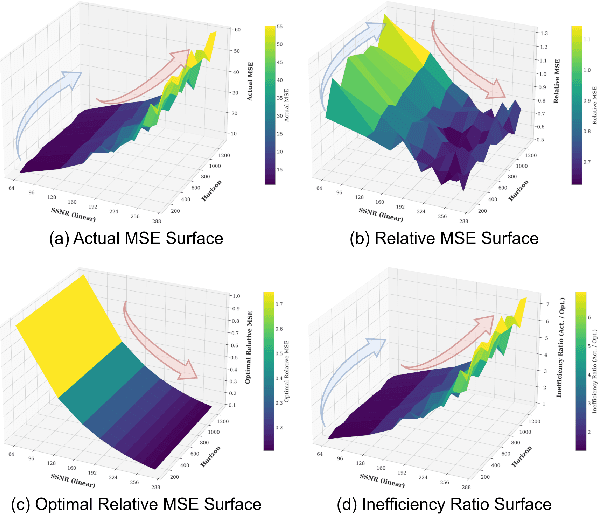
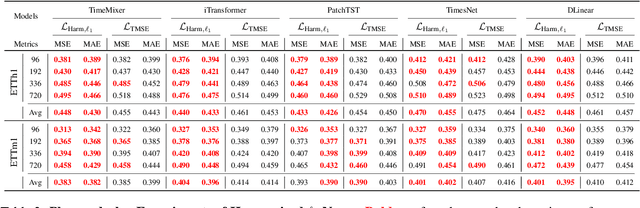
Optimizing time series models via point-wise loss functions (e.g., MSE) relying on a flawed point-wise independent and identically distributed (i.i.d.) assumption that disregards the causal temporal structure, an issue with growing awareness yet lacking formal theoretical grounding. Focusing on the core independence issue under covariance stationarity, this paper aims to provide a first-principles analysis of the Expectation of Optimization Bias (EOB), formalizing it information-theoretically as the discrepancy between the true joint distribution and its flawed i.i.d. counterpart. Our analysis reveals a fundamental paradigm paradox: the more deterministic and structured the time series, the more severe the bias by point-wise loss function. We derive the first closed-form quantification for the non-deterministic EOB across linear and non-linear systems, and prove EOB is an intrinsic data property, governed exclusively by sequence length and our proposed Structural Signal-to-Noise Ratio (SSNR). This theoretical diagnosis motivates our principled debiasing program that eliminates the bias through sequence length reduction and structural orthogonalization. We present a concrete solution that simultaneously achieves both principles via DFT or DWT. Furthermore, a novel harmonized $\ell_p$ norm framework is proposed to rectify gradient pathologies of high-variance series. Extensive experiments validate EOB Theory's generality and the superior performance of debiasing program.
IG2: Integrated Gradient on Iterative Gradient Path for Feature Attribution
Jun 16, 2024Feature attribution explains Artificial Intelligence (AI) at the instance level by providing importance scores of input features' contributions to model prediction. Integrated Gradients (IG) is a prominent path attribution method for deep neural networks, involving the integration of gradients along a path from the explained input (explicand) to a counterfactual instance (baseline). Current IG variants primarily focus on the gradient of explicand's output. However, our research indicates that the gradient of the counterfactual output significantly affects feature attribution as well. To achieve this, we propose Iterative Gradient path Integrated Gradients (IG2), considering both gradients. IG2 incorporates the counterfactual gradient iteratively into the integration path, generating a novel path (GradPath) and a novel baseline (GradCF). These two novel IG components effectively address the issues of attribution noise and arbitrary baseline choice in earlier IG methods. IG2, as a path method, satisfies many desirable axioms, which are theoretically justified in the paper. Experimental results on XAI benchmark, ImageNet, MNIST, TREC questions answering, wafer-map failure patterns, and CelebA face attributes validate that IG2 delivers superior feature attributions compared to the state-of-the-art techniques. The code is released at: https://github.com/JoeZhuo-ZY/IG2.
ABIGX: A Unified Framework for eXplainable Fault Detection and Classification
Nov 09, 2023For explainable fault detection and classification (FDC), this paper proposes a unified framework, ABIGX (Adversarial fault reconstruction-Based Integrated Gradient eXplanation). ABIGX is derived from the essentials of previous successful fault diagnosis methods, contribution plots (CP) and reconstruction-based contribution (RBC). It is the first explanation framework that provides variable contributions for the general FDC models. The core part of ABIGX is the adversarial fault reconstruction (AFR) method, which rethinks the FR from the perspective of adversarial attack and generalizes to fault classification models with a new fault index. For fault classification, we put forward a new problem of fault class smearing, which intrinsically hinders the correct explanation. We prove that ABIGX effectively mitigates this problem and outperforms the existing gradient-based explanation methods. For fault detection, we theoretically bridge ABIGX with conventional fault diagnosis methods by proving that CP and RBC are the linear specifications of ABIGX. The experiments evaluate the explanations of FDC by quantitative metrics and intuitive illustrations, the results of which show the general superiority of ABIGX to other advanced explanation methods.
Directed Acyclic Graphs With Tears
Feb 04, 2023



Bayesian network is a frequently-used method for fault detection and diagnosis in industrial processes. The basis of Bayesian network is structure learning which learns a directed acyclic graph (DAG) from data. However, the search space will scale super-exponentially with the increase of process variables, which makes the data-driven structure learning a challenging problem. To this end, the DAGs with NOTEARs methods are being well studied not only for their conversion of the discrete optimization into continuous optimization problem but also their compatibility with deep learning framework. Nevertheless, there still remain challenges for NOTEAR-based methods: 1) the infeasible solution results from the gradient descent-based optimization paradigm; 2) the truncation operation to promise the learned graph acyclic. In this work, the reason for challenge 1) is analyzed theoretically, and a novel method named DAGs with Tears method is proposed based on mix-integer programming to alleviate challenge 2). In addition, prior knowledge is able to incorporate into the new proposed method, making structure learning more practical and useful in industrial processes. Finally, a numerical example and an industrial example are adopted as case studies to demonstrate the superiority of the developed method.
Latent Variable Models in the Era of Industrial Big Data: Extension and Beyond
Aug 23, 2022
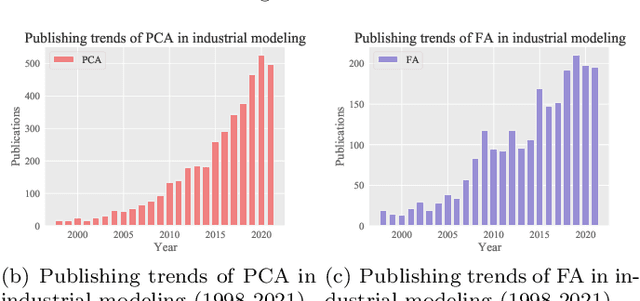
A rich supply of data and innovative algorithms have made data-driven modeling a popular technique in modern industry. Among various data-driven methods, latent variable models (LVMs) and their counterparts account for a major share and play a vital role in many industrial modeling areas. LVM can be generally divided into statistical learning-based classic LVM and neural networks-based deep LVM (DLVM). We first discuss the definitions, theories and applications of classic LVMs in detail, which serves as both a comprehensive tutorial and a brief application survey on classic LVMs. Then we present a thorough introduction to current mainstream DLVMs with emphasis on their theories and model architectures, soon afterwards provide a detailed survey on industrial applications of DLVMs. The aforementioned two types of LVM have obvious advantages and disadvantages. Specifically, classic LVMs have concise principles and good interpretability, but their model capacity cannot address complicated tasks. Neural networks-based DLVMs have sufficient model capacity to achieve satisfactory performance in complex scenarios, but it comes at sacrifices in model interpretability and efficiency. Aiming at combining the virtues and mitigating the drawbacks of these two types of LVMs, as well as exploring non-neural-network manners to build deep models, we propose a novel concept called lightweight deep LVM (LDLVM). After proposing this new idea, the article first elaborates the motivation and connotation of LDLVM, then provides two novel LDLVMs, along with thorough descriptions on their principles, architectures and merits. Finally, outlooks and opportunities are discussed, including important open questions and possible research directions.