 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgainst All Odds: Overcoming Typology, Script, and Language Confusion in Multilingual Embedding Inversion Attacks
Paper and Code
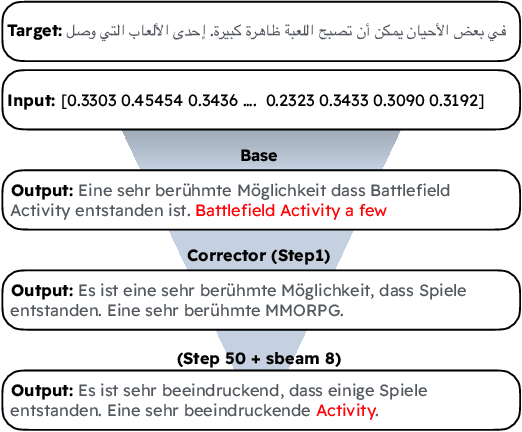
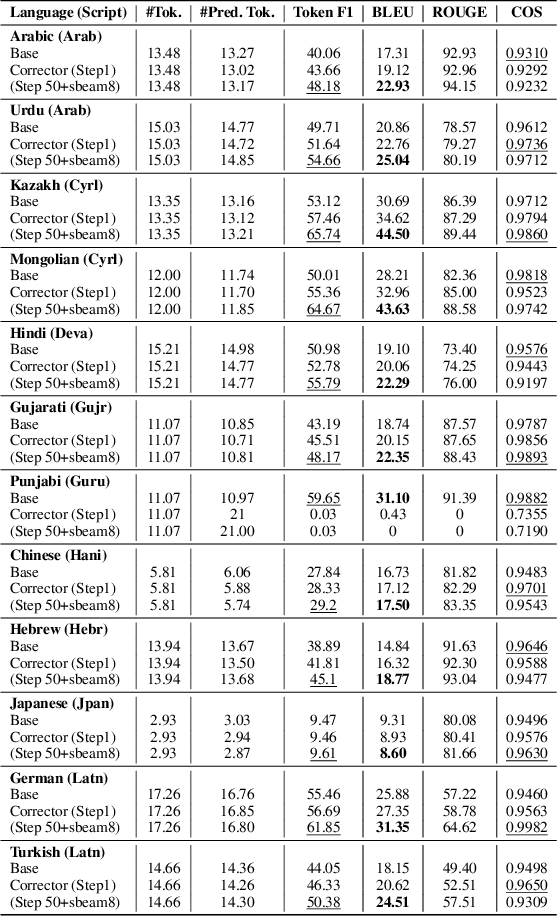

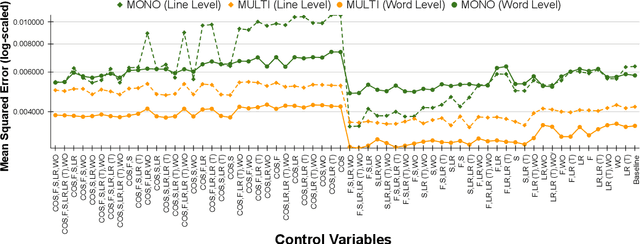
Large Language Models (LLMs) are susceptible to malicious influence by cyber attackers through intrusions such as adversarial, backdoor, and embedding inversion attacks. In response, the burgeoning field of LLM Security aims to study and defend against such threats. Thus far, the majority of works in this area have focused on monolingual English models, however, emerging research suggests that multilingual LLMs may be more vulnerable to various attacks than their monolingual counterparts. While previous work has investigated embedding inversion over a small subset of European languages, it is challenging to extrapolate these findings to languages from different linguistic families and with differing scripts. To this end, we explore the security of multilingual LLMs in the context of embedding inversion attacks and investigate cross-lingual and cross-script inversion across 20 languages, spanning over 8 language families and 12 scripts. Our findings indicate that languages written in Arabic script and Cyrillic script are particularly vulnerable to embedding inversion, as are languages within the Indo-Aryan language family. We further observe that inversion models tend to suffer from language confusion, sometimes greatly reducing the efficacy of an attack. Accordingly, we systematically explore this bottleneck for inversion models, uncovering predictable patterns which could be leveraged by attackers. Ultimately, this study aims to further the field's understanding of the outstanding security vulnerabilities facing multilingual LLMs and raise awareness for the languages most at risk of negative impact from these attacks.