 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Embedding Inversion Attacks on Multilingual Language Models
Paper and Code
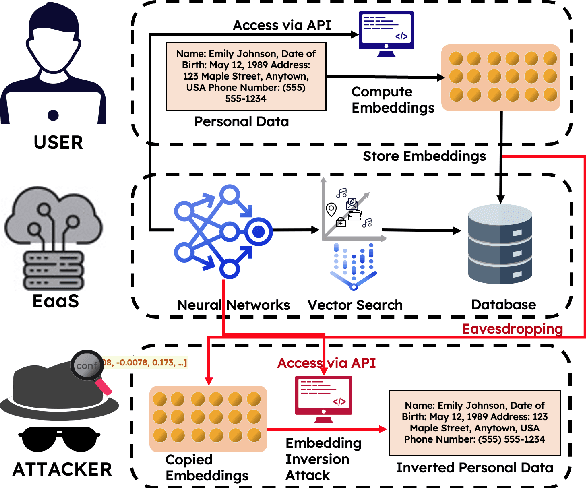
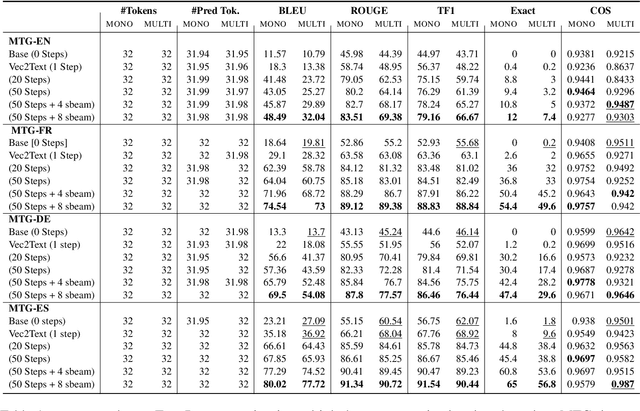
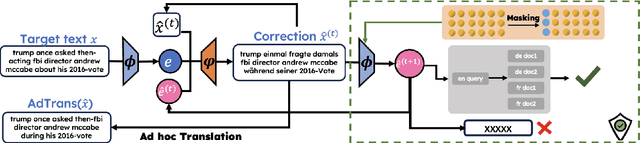
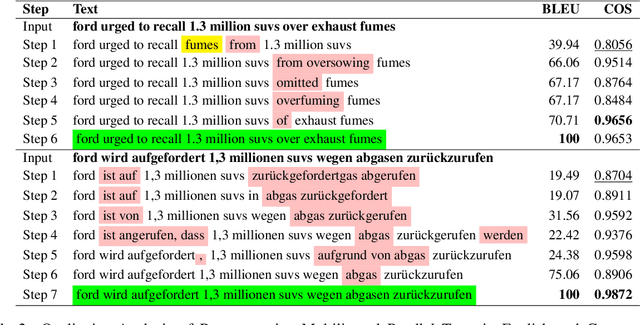
Representing textual information as real-numbered embeddings has become the norm in NLP. Moreover, with the rise of public interest in large language models (LLMs), Embeddings as a Service (EaaS) has rapidly gained traction as a business model. This is not without outstanding security risks, as previous research has demonstrated that sensitive data can be reconstructed from embeddings, even without knowledge of the underlying model that generated them. However, such work is limited by its sole focus on English, leaving all other languages vulnerable to attacks by malicious actors. %As many international and multilingual companies leverage EaaS, there is an urgent need for research into multilingual LLM security. To this end, this work investigates LLM security from the perspective of multilingual embedding inversion. Concretely, we define the problem of black-box multilingual and cross-lingual inversion attacks, with special attention to a cross-domain scenario. Our findings reveal that multilingual models are potentially more vulnerable to inversion attacks than their monolingual counterparts. This stems from the reduced data requirements for achieving comparable inversion performance in settings where the underlying language is not known a-priori. To our knowledge, this work is the first to delve into multilinguality within the context of inversion attacks, and our findings highlight the need for further investigation and enhanced defenses in the area of NLP Security.