 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Easily Confused: A Quantitative Metric, Security Implications and Typological Analysis
Paper and Code

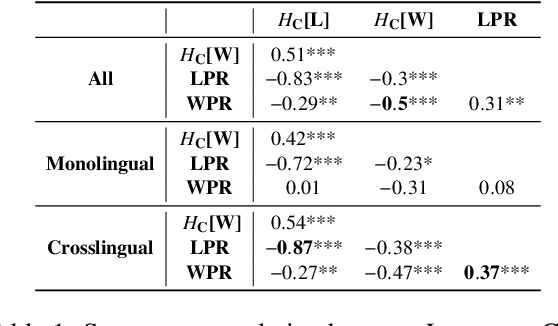

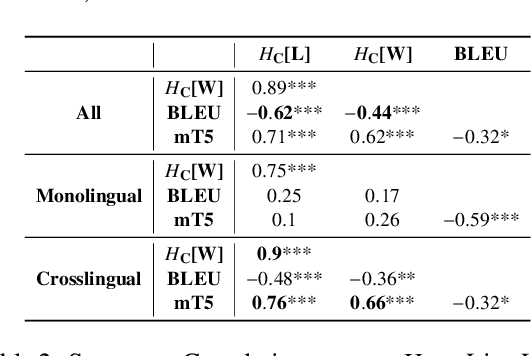
Language Confusion is a phenomenon where Large Language Models (LLMs) generate text that is neither in the desired language, nor in a contextually appropriate language. This phenomenon presents a critical challenge in text generation by LLMs, often appearing as erratic and unpredictable behavior. We hypothesize that there are linguistic regularities to this inherent vulnerability in LLMs and shed light on patterns of language confusion across LLMs. We introduce a novel metric, Language Confusion Entropy, designed to directly measure and quantify this confusion, based on language distributions informed by linguistic typology and lexical variation. Comprehensive comparisons with the Language Confusion Benchmark (Marchisio et al., 2024) confirm the effectiveness of our metric, revealing patterns of language confusion across LLMs. We further link language confusion to LLM security, and find patterns in the case of multilingual embedding inversion attacks. Our analysis demonstrates that linguistic typology offers theoretically grounded interpretation, and valuable insights into leveraging language similarities as a prior for LLM alignment and security.