 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting and Encoding: Leveraging Large Language Models and Medical Knowledge to Enhance Radiological Text Representation
Paper and Code

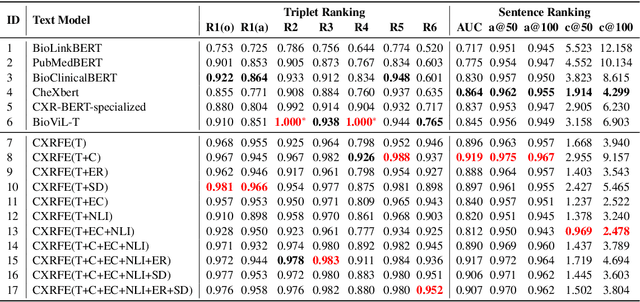
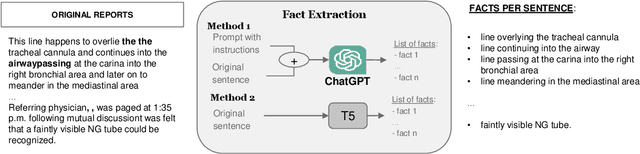
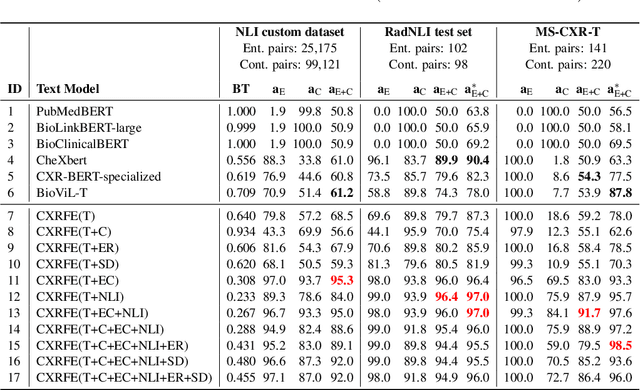
Advancing representation learning in specialized fields like medicine remains challenging due to the scarcity of expert annotations for text and images. To tackle this issue, we present a novel two-stage framework designed to extract high-quality factual statements from free-text radiology reports in order to improve the representations of text encoders and, consequently, their performance on various downstream tasks. In the first stage, we propose a \textit{Fact Extractor} that leverages large language models (LLMs) to identify factual statements from well-curated domain-specific datasets. In the second stage, we introduce a \textit{Fact Encoder} (CXRFE) based on a BERT model fine-tuned with objective functions designed to improve its representations using the extracted factual data. Our framework also includes a new embedding-based metric (CXRFEScore) for evaluating chest X-ray text generation systems, leveraging both stages of our approach. Extensive evaluations show that our fact extractor and encoder outperform current state-of-the-art methods in tasks such as sentence ranking, natural language inference, and label extraction from radiology reports. Additionally, our metric proves to be more robust and effective than existing metrics commonly used in the radiology report generation literature. The code of this project is available at \url{https://github.com/PabloMessina/CXR-Fact-Encoder}.