Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Detection and Understanding of Fictional Discourse
Paper and Code

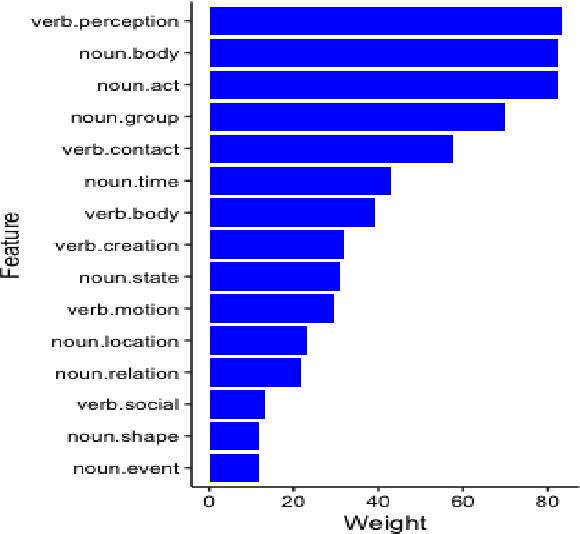


In this paper, we present a variety of classification experiments related to the task of fictional discourse detection. We utilize a diverse array of datasets, including contemporary professionally published fiction, historical fiction from the Hathi Trust, fanfiction, stories from Reddit, folk tales, GPT-generated stories, and anglophone world literature. Additionally, we introduce a new feature set of word "supersenses" that facilitate the goal of semantic generalization. The detection of fictional discourse can help enrich our knowledge of large cultural heritage archives and assist with the process of understanding the distinctive qualities of fictional storytelling more broadly.
View paper on