Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5 meets Tybalt: Author Attribution in Early Modern English Drama Using Large Language Models
Paper and Code

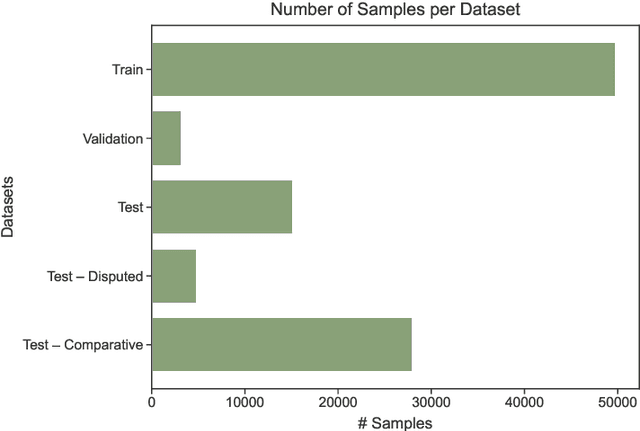
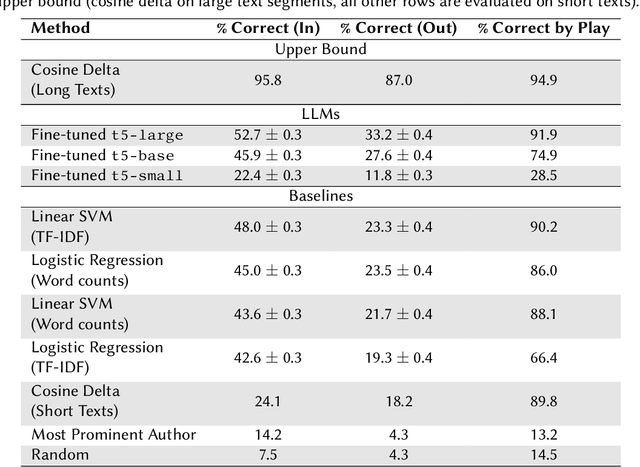
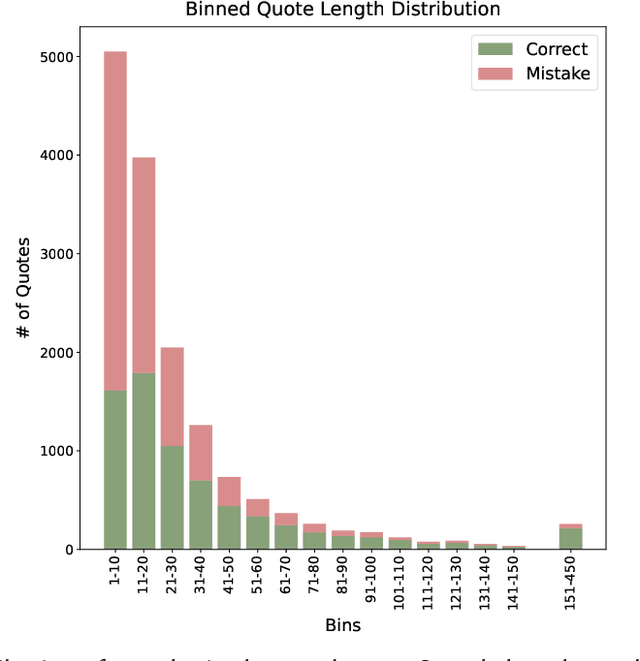
Large language models have shown breakthrough potential in many NLP domains. Here we consider their use for stylometry, specifically authorship identification in Early Modern English drama. We find both promising and concerning results; LLMs are able to accurately predict the author of surprisingly short passages but are also prone to confidently misattribute texts to specific authors. A fine-tuned t5-large model outperforms all tested baselines, including logistic regression, SVM with a linear kernel, and cosine delta, at attributing small passages. However, we see indications that the presence of certain authors in the model's pre-training data affects predictive results in ways that are difficult to assess.
* Published in CHR 2023
View paper on