 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High-Quality Image Segmentation: Improving Topology Accuracy by Penalizing Neighbor Pixels
Mar 19, 2026Standard deep learning models for image segmentation cannot guarantee topology accuracy, failing to preserve the correct number of connected components or structures. This, in turn, affects the quality of the segmentations and compromises the reliability of the subsequent quantification analyses. Previous works have proposed to enhance topology accuracy with specialized frameworks, architectures, and loss functions. However, these methods are often cumbersome to integrate into existing training pipelines, they are computationally very expensive, or they are restricted to structures with tubular morphology. We present SCNP, an efficient method that improves topology accuracy by penalizing the logits with their poorest-classified neighbor, forcing the model to improve the prediction at the pixels' neighbors before allowing it to improve the pixels themselves. We show the effectiveness of SCNP across 13 datasets, covering different structure morphologies and image modalities, and integrate it into three frameworks for semantic and instance segmentation. Additionally, we show that SCNP can be integrated into several loss functions, making them improve topology accuracy. Our code can be found at https://jmlipman.github.io/SCNP-SameClassNeighborPenalization.
Danish Foundation Models
Nov 13, 2023

Large language models, sometimes referred to as foundation models, have transformed multiple fields of research. However, smaller languages risk falling behind due to high training costs and small incentives for large companies to train these models. To combat this, the Danish Foundation Models project seeks to provide and maintain open, well-documented, and high-quality foundation models for the Danish language. This is achieved through broad cooperation with public and private institutions, to ensure high data quality and applicability of the trained models. We present the motivation of the project, the current status, and future perspectives.
Programmatic Policy Extraction by Iterative Local Search
Jan 18, 2022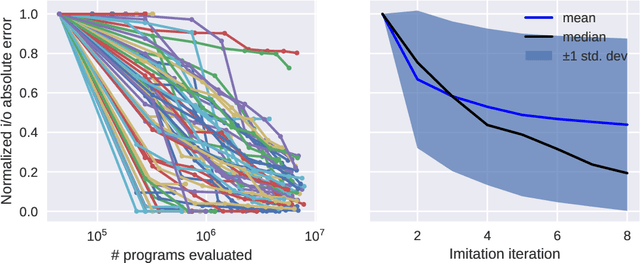
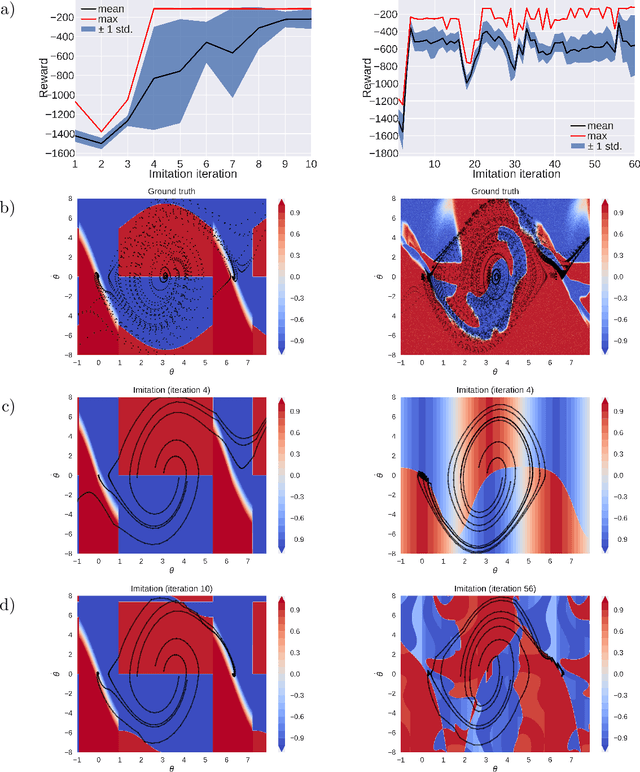
Reinforcement learning policies are often represented by neural networks, but programmatic policies are preferred in some cases because they are more interpretable, amenable to formal verification, or generalize better. While efficient algorithms for learning neural policies exist, learning programmatic policies is challenging. Combining imitation-projection and dataset aggregation with a local search heuristic, we present a simple and direct approach to extracting a programmatic policy from a pretrained neural policy. After examining our local search heuristic on a programming by example problem, we demonstrate our programmatic policy extraction method on a pendulum swing-up problem. Both when trained using a hand crafted expert policy and a learned neural policy, our method discovers simple and interpretable policies that perform almost as well as the original.
Device Placement Optimization with Reinforcement Learning
Jun 25, 2017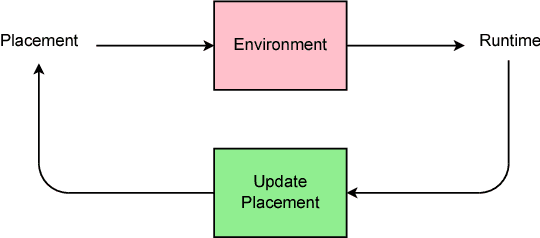
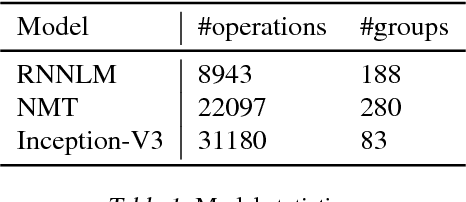
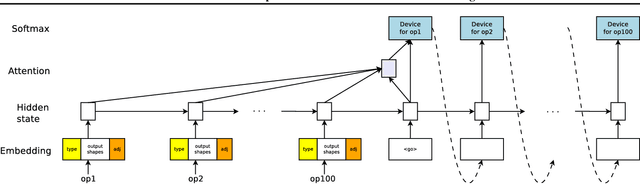
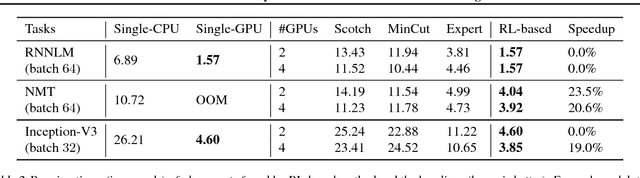
The past few years have witnessed a growth in size and computational requirements for training and inference with neural networks. Currently, a common approach to address these requirements is to use a heterogeneous distributed environment with a mixture of hardware devices such as CPUs and GPUs. Importantly, the decision of placing parts of the neural models on devices is often made by human experts based on simple heuristics and intuitions. In this paper, we propose a method which learns to optimize device placement for TensorFlow computational graphs. Key to our method is the use of a sequence-to-sequence model to predict which subsets of operations in a TensorFlow graph should run on which of the available devices. The execution time of the predicted placements is then used as the reward signal to optimize the parameters of the sequence-to-sequence model. Our main result is that on Inception-V3 for ImageNet classification, and on RNN LSTM, for language modeling and neural machine translation, our model finds non-trivial device placements that outperform hand-crafted heuristics and traditional algorithmic methods.