 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgrammatic Policy Extraction by Iterative Local Search
Paper and Code
Jan 18, 2022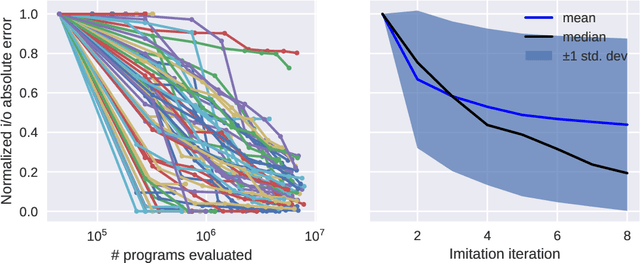
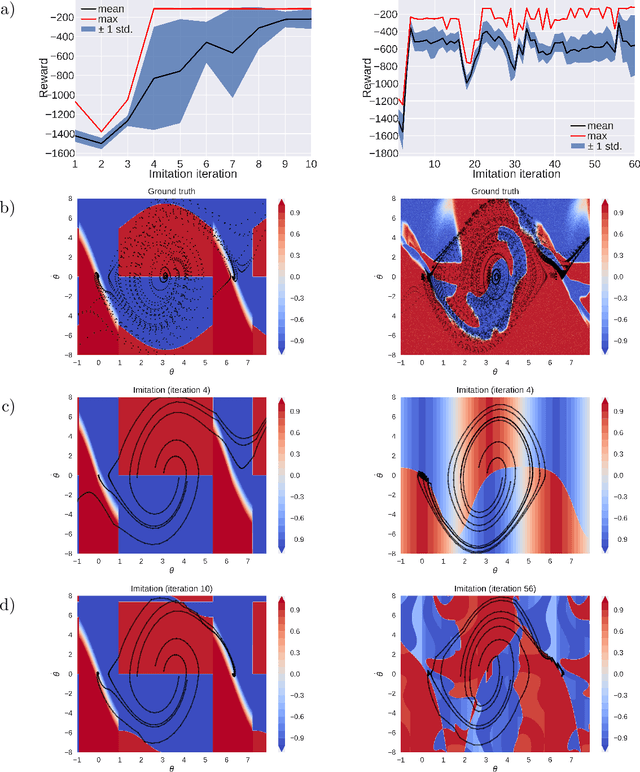
Reinforcement learning policies are often represented by neural networks, but programmatic policies are preferred in some cases because they are more interpretable, amenable to formal verification, or generalize better. While efficient algorithms for learning neural policies exist, learning programmatic policies is challenging. Combining imitation-projection and dataset aggregation with a local search heuristic, we present a simple and direct approach to extracting a programmatic policy from a pretrained neural policy. After examining our local search heuristic on a programming by example problem, we demonstrate our programmatic policy extraction method on a pendulum swing-up problem. Both when trained using a hand crafted expert policy and a learned neural policy, our method discovers simple and interpretable policies that perform almost as well as the original.