 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynomaly Noise and Multi-Stage Diffusion: A Novel Approach for Unsupervised Anomaly Detection in Ultrasound Imaging
Nov 06, 2024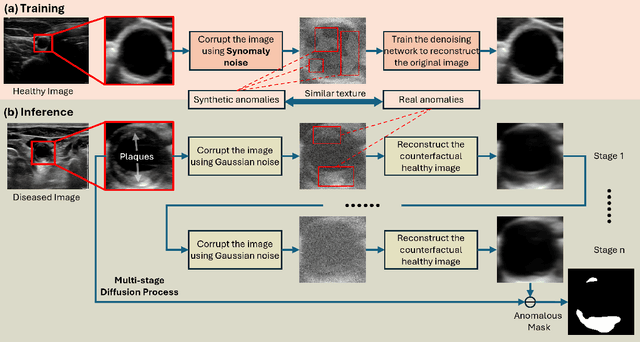
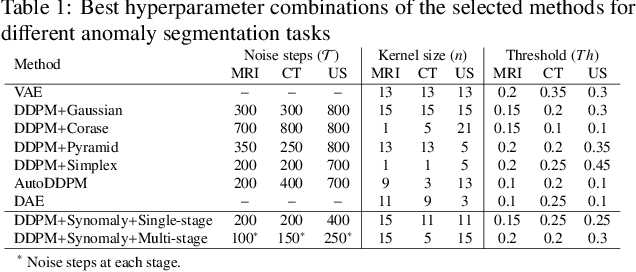
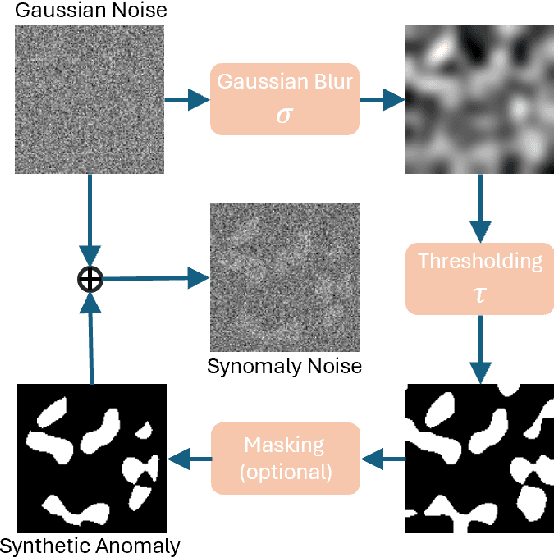
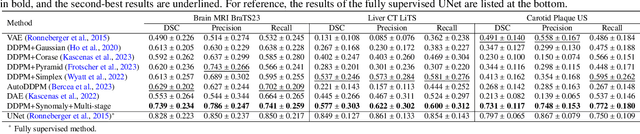
Ultrasound (US) imaging is widely used in routine clinical practice due to its advantages of being radiation-free, cost-effective, and portable. However, the low reproducibility and quality of US images, combined with the scarcity of expert-level annotation, make the training of fully supervised segmentation models challenging. To address these issues, we propose a novel unsupervised anomaly detection framework based on a diffusion model that incorporates a synthetic anomaly (Synomaly) noise function and a multi-stage diffusion process. Synomaly noise introduces synthetic anomalies into healthy images during training, allowing the model to effectively learn anomaly removal. The multi-stage diffusion process is introduced to progressively denoise images, preserving fine details while improving the quality of anomaly-free reconstructions. The generated high-fidelity counterfactual healthy images can further enhance the interpretability of the segmentation models, as well as provide a reliable baseline for evaluating the extent of anomalies and supporting clinical decision-making. Notably, the unsupervised anomaly detection model is trained purely on healthy images, eliminating the need for anomalous training samples and pixel-level annotations. We validate the proposed approach on carotid US, brain MRI, and liver CT datasets. The experimental results demonstrate that the proposed framework outperforms existing state-of-the-art unsupervised anomaly detection methods, achieving performance comparable to fully supervised segmentation models in the US dataset. Additionally, ablation studies underline the importance of hyperparameter selection for Synomaly noise and the effectiveness of the multi-stage diffusion process in enhancing model performance.
MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
Mar 22, 2023Generalization capabilities of learning-based medical image segmentation across domains are currently limited by the performance degradation caused by the domain shift, particularly for ultrasound (US) imaging. The quality of US images heavily relies on carefully tuned acoustic parameters, which vary across sonographers, machines, and settings. To improve the generalizability on US images across domains, we propose MI-SegNet, a novel mutual information (MI) based framework to explicitly disentangle the anatomical and domain feature representations; therefore, robust domain-independent segmentation can be expected. Two encoders are employed to extract the relevant features for the disentanglement. The segmentation only uses the anatomical feature map for its prediction. In order to force the encoders to learn meaningful feature representations a cross-reconstruction method is used during training. Transformations, specific to either domain or anatomy are applied to guide the encoders in their respective feature extraction task. Additionally, any MI present in both feature maps is punished to further promote separate feature spaces. We validate the generalizability of the proposed domain-independent segmentation approach on several datasets with varying parameters and machines. Furthermore, we demonstrate the effectiveness of the proposed MI-SegNet serving as a pre-trained model by comparing it with state-of-the-art networks.