 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Label Enhancement
Paper and Code
May 16, 2023
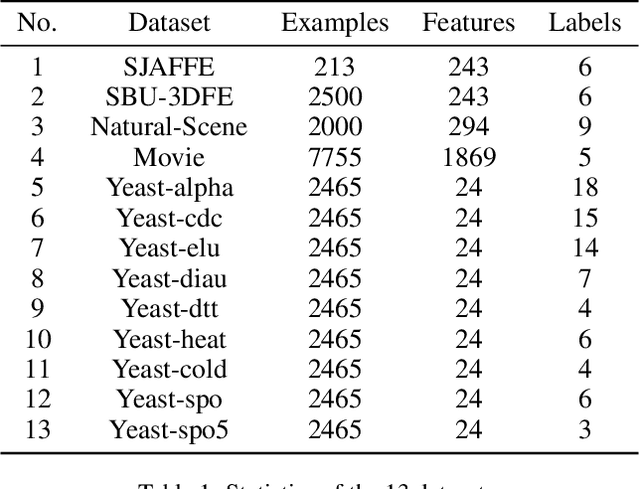
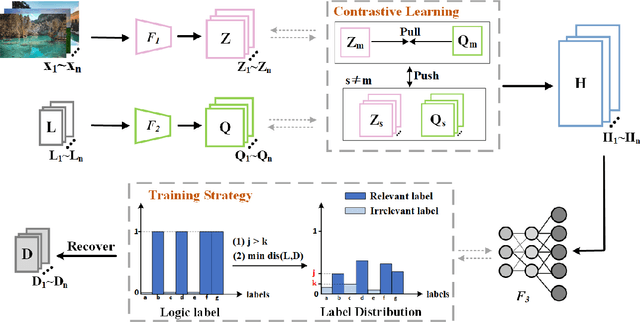

Label distribution learning (LDL) is a new machine learning paradigm for solving label ambiguity. Since it is difficult to directly obtain label distributions, many studies are focusing on how to recover label distributions from logical labels, dubbed label enhancement (LE). Existing LE methods estimate label distributions by simply building a mapping relationship between features and label distributions under the supervision of logical labels. They typically overlook the fact that both features and logical labels are descriptions of the instance from different views. Therefore, we propose a novel method called Contrastive Label Enhancement (ConLE) which integrates features and logical labels into the unified projection space to generate high-level features by contrastive learning strategy. In this approach, features and logical labels belonging to the same sample are pulled closer, while those of different samples are projected farther away from each other in the projection space. Subsequently, we leverage the obtained high-level features to gain label distributions through a welldesigned training strategy that considers the consistency of label attributes. Extensive experiments on LDL benchmark datasets demonstrate the effectiveness and superiority of our method.