 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Convolutional Grasp Detection Network with Oriented Anchor Box
Paper and Code
Mar 06, 2018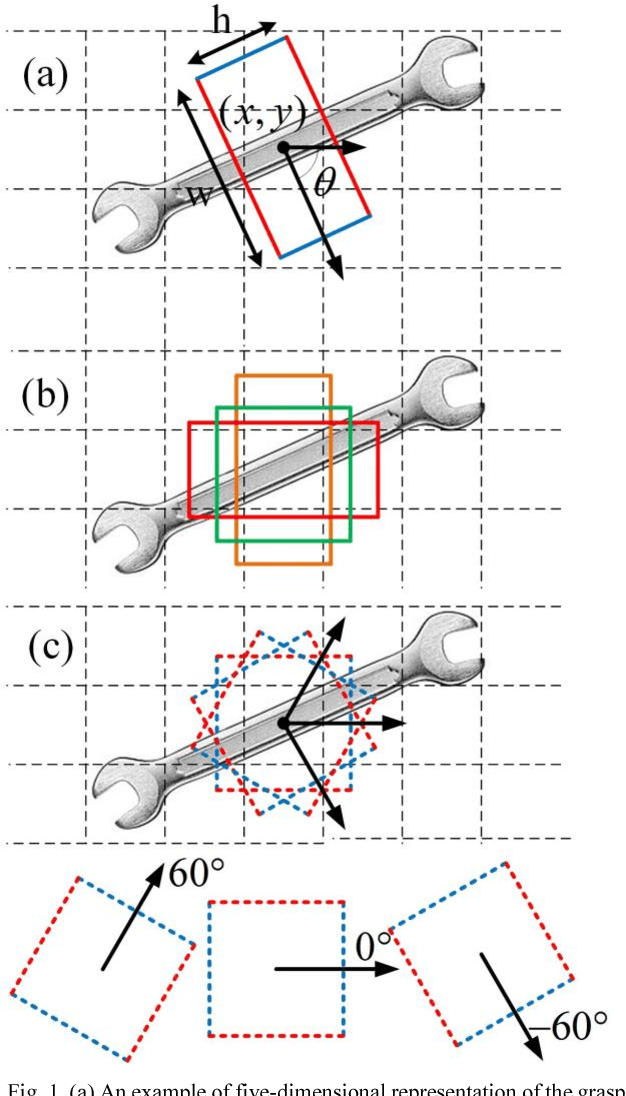
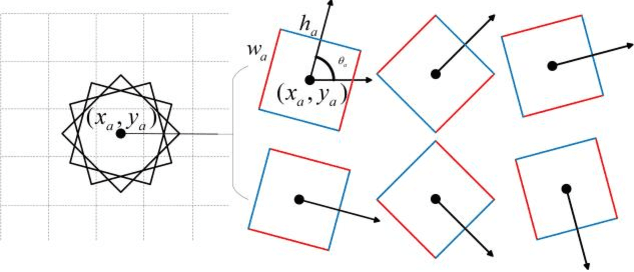
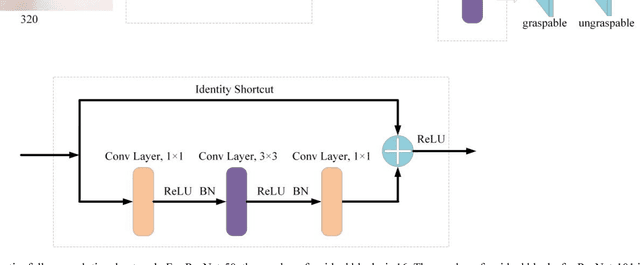

In this paper, we present a real-time approach to predict multiple grasping poses for a parallel-plate robotic gripper using RGB images. A model with oriented anchor box mechanism is proposed and a new matching strategy is used during the training process. An end-to-end fully convolutional neural network is employed in our work. The network consists of two parts: the feature extractor and multi-grasp predictor. The feature extractor is a deep convolutional neural network. The multi-grasp predictor regresses grasp rectangles from predefined oriented rectangles, called oriented anchor boxes, and classifies the rectangles into graspable and ungraspable. On the standard Cornell Grasp Dataset, our model achieves an accuracy of 97.74% and 96.61% on image-wise split and object-wise split respectively, and outperforms the latest state-of-the-art approach by 1.74% on image-wise split and 0.51% on object-wise split.