 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning High-level Prior with Convolutional Neural Networks for Semantic Segmentation
Paper and Code
Nov 22, 2015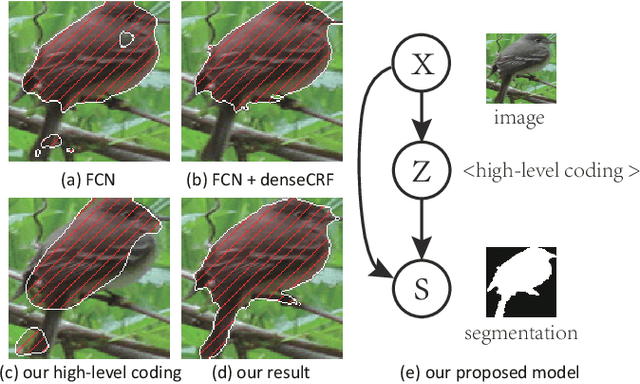
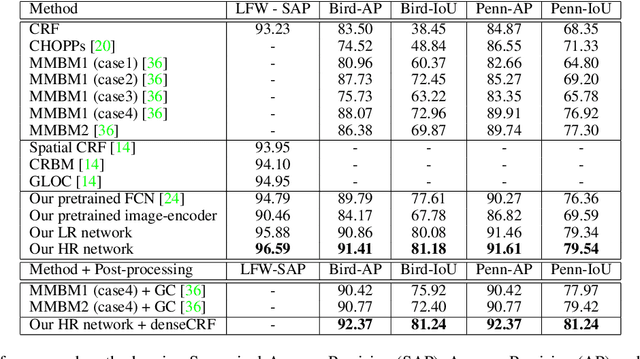
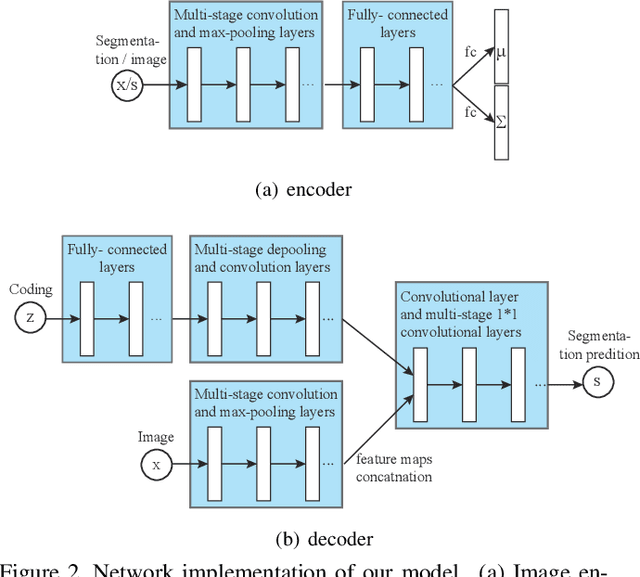
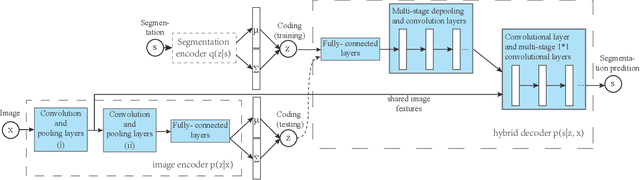
This paper proposes a convolutional neural network that can fuse high-level prior for semantic image segmentation. Motivated by humans' vision recognition system, our key design is a three-layer generative structure consisting of high-level coding, middle-level segmentation and low-level image to introduce global prior for semantic segmentation. Based on this structure, we proposed a generative model called conditional variational auto-encoder (CVAE) that can build up the links behind these three layers. These important links include an image encoder that extracts high level info from image, a segmentation encoder that extracts high level info from segmentation, and a hybrid decoder that outputs semantic segmentation from the high level prior and input image. We theoretically derive the semantic segmentation as an optimization problem parameterized by these links. Finally, the optimization problem enables us to take advantage of state-of-the-art fully convolutional network structure for the implementation of the above encoders and decoder. Experimental results on several representative datasets demonstrate our supreme performance for semantic segmentation.