 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Multi-Robot Cooperation via Sequential World Models
Sep 16, 2025Model-based reinforcement learning (MBRL) has shown significant potential in robotics due to its high sample efficiency and planning capability. However, extending MBRL to multi-robot cooperation remains challenging due to the complexity of joint dynamics. To address this, we propose the Sequential World Model (SeqWM), a novel framework that integrates the sequential paradigm into model-based multi-agent reinforcement learning. SeqWM employs independent, sequentially structured agent-wise world models to decompose complex joint dynamics. Latent rollouts and decision-making are performed through sequential communication, where each agent generates its future trajectory and plans its actions based on the predictions of its predecessors. This design enables explicit intention sharing, enhancing cooperative performance, and reduces communication overhead to linear complexity. Results in challenging simulated environments (Bi-DexHands and Multi-Quad) show that SeqWM outperforms existing state-of-the-art model-free and model-based baselines in both overall performance and sample efficiency, while exhibiting advanced cooperative behaviors such as predictive adaptation and role division. Furthermore, SeqWM has been success fully deployed on physical quadruped robots, demonstrating its effectiveness in real-world multi-robot systems. Demos and code are available at: https://github.com/zhaozijie2022/seqwm-marl
Feel the Difference? A Comparative Analysis of Emotional Arcs in Real and LLM-Generated CBT Sessions
Aug 28, 2025Synthetic therapy dialogues generated by large language models (LLMs) are increasingly used in mental health NLP to simulate counseling scenarios, train models, and supplement limited real-world data. However, it remains unclear whether these synthetic conversations capture the nuanced emotional dynamics of real therapy. In this work, we conduct the first comparative analysis of emotional arcs between real and LLM-generated Cognitive Behavioral Therapy dialogues. We adapt the Utterance Emotion Dynamics framework to analyze fine-grained affective trajectories across valence, arousal, and dominance dimensions. Our analysis spans both full dialogues and individual speaker roles (counselor and client), using real sessions transcribed from public videos and synthetic dialogues from the CACTUS dataset. We find that while synthetic dialogues are fluent and structurally coherent, they diverge from real conversations in key emotional properties: real sessions exhibit greater emotional variability,more emotion-laden language, and more authentic patterns of reactivity and regulation. Moreover, emotional arc similarity between real and synthetic speakers is low, especially for clients. These findings underscore the limitations of current LLM-generated therapy data and highlight the importance of emotional fidelity in mental health applications. We introduce RealCBT, a curated dataset of real CBT sessions, to support future research in this space.
Context-aware Talking Face Video Generation
Feb 28, 2024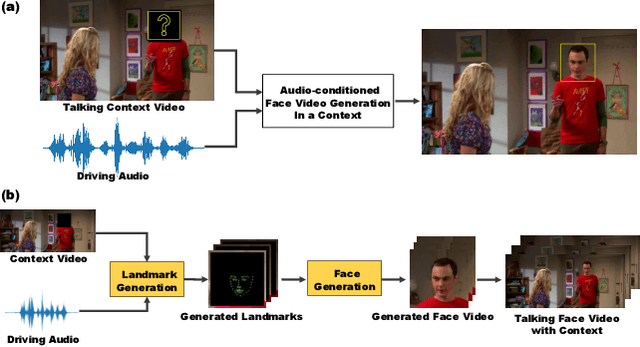
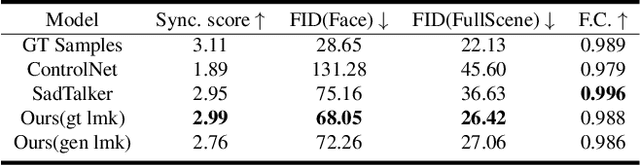
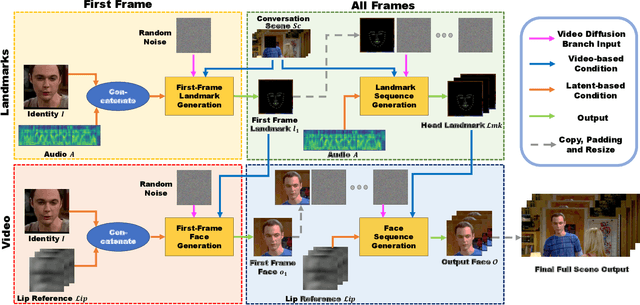
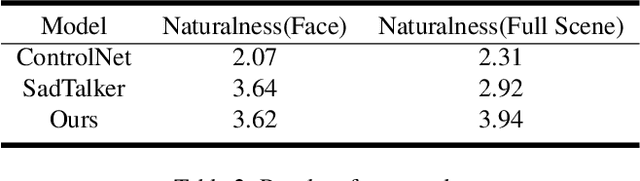
In this paper, we consider a novel and practical case for talking face video generation. Specifically, we focus on the scenarios involving multi-people interactions, where the talking context, such as audience or surroundings, is present. In these situations, the video generation should take the context into consideration in order to generate video content naturally aligned with driving audios and spatially coherent to the context. To achieve this, we provide a two-stage and cross-modal controllable video generation pipeline, taking facial landmarks as an explicit and compact control signal to bridge the driving audio, talking context and generated videos. Inside this pipeline, we devise a 3D video diffusion model, allowing for efficient contort of both spatial conditions (landmarks and context video), as well as audio condition for temporally coherent generation. The experimental results verify the advantage of the proposed method over other baselines in terms of audio-video synchronization, video fidelity and frame consistency.
Hi Sheldon! Creating Deep Personalized Characters from TV Shows
Apr 09, 2023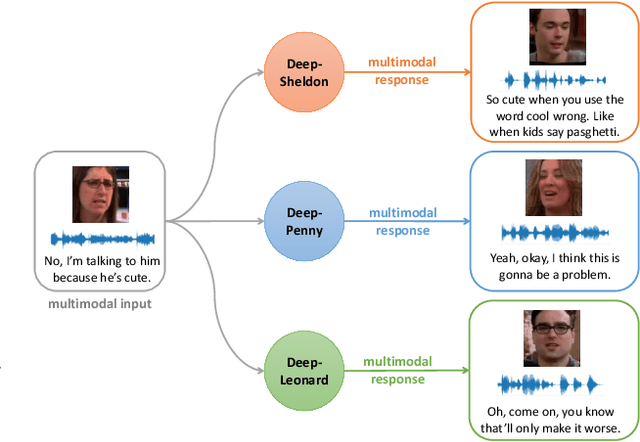
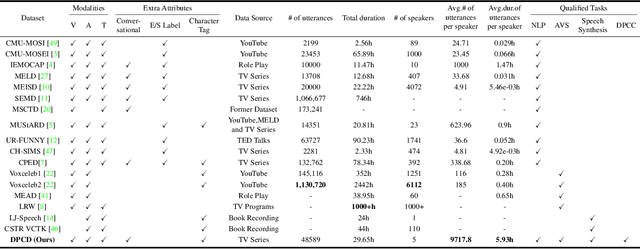
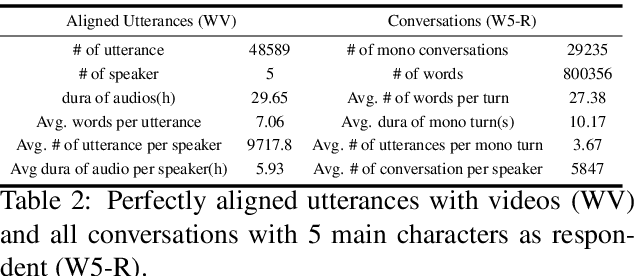
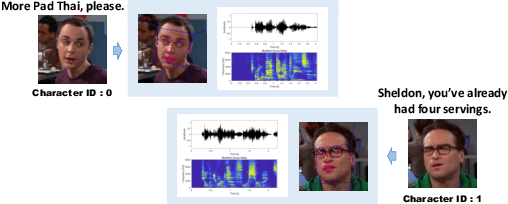
Imagine an interesting multimodal interactive scenario that you can see, hear, and chat with an AI-generated digital character, who is capable of behaving like Sheldon from The Big Bang Theory, as a DEEP copy from appearance to personality. Towards this fantastic multimodal chatting scenario, we propose a novel task, named Deep Personalized Character Creation (DPCC): creating multimodal chat personalized characters from multimodal data such as TV shows. Specifically, given a single- or multi-modality input (text, audio, video), the goal of DPCC is to generate a multi-modality (text, audio, video) response, which should be well-matched the personality of a specific character such as Sheldon, and of high quality as well. To support this novel task, we further collect a character centric multimodal dialogue dataset, named Deep Personalized Character Dataset (DPCD), from TV shows. DPCD contains character-specific multimodal dialogue data of ~10k utterances and ~6 hours of audio/video per character, which is around 10 times larger compared to existing related datasets.On DPCD, we present a baseline method for the DPCC task and create 5 Deep personalized digital Characters (DeepCharacters) from Big Bang TV Shows. We conduct both subjective and objective experiments to evaluate the multimodal response from DeepCharacters in terms of characterization and quality. The results demonstrates that, on our collected DPCD dataset, the proposed baseline can create personalized digital characters for generating multimodal response.Our collected DPCD dataset, the code of data collection and our baseline will be published soon.
Efficient Mind-Map Generation via Sequence-to-Graph and Reinforced Graph Refinement
Sep 06, 2021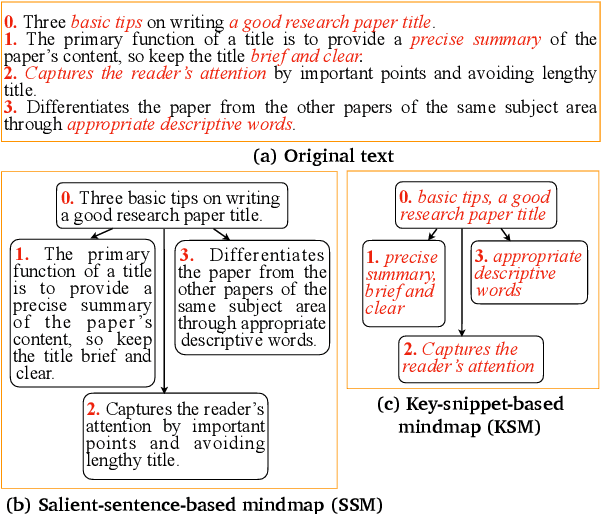
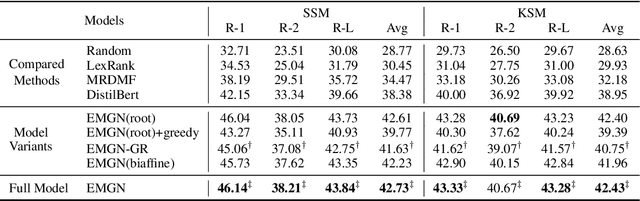
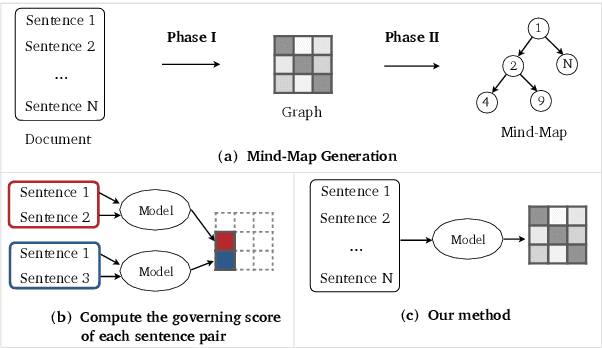
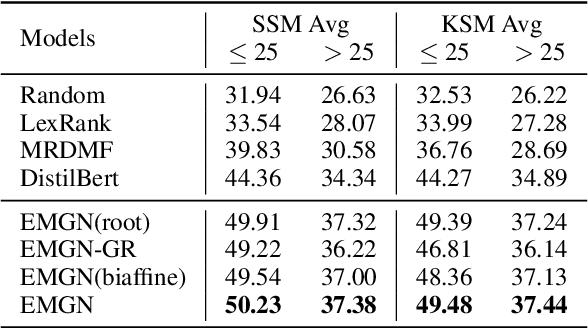
A mind-map is a diagram that represents the central concept and key ideas in a hierarchical way. Converting plain text into a mind-map will reveal its key semantic structure and be easier to understand. Given a document, the existing automatic mind-map generation method extracts the relationships of every sentence pair to generate the directed semantic graph for this document. The computation complexity increases exponentially with the length of the document. Moreover, it is difficult to capture the overall semantics. To deal with the above challenges, we propose an efficient mind-map generation network that converts a document into a graph via sequence-to-graph. To guarantee a meaningful mind-map, we design a graph refinement module to adjust the relation graph in a reinforcement learning manner. Extensive experimental results demonstrate that the proposed approach is more effective and efficient than the existing methods. The inference time is reduced by thousands of times compared with the existing methods. The case studies verify that the generated mind-maps better reveal the underlying semantic structures of the document.
Multi-Label Few-Shot Learning for Aspect Category Detection
May 29, 2021

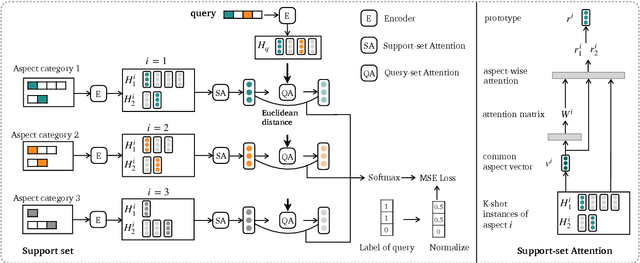
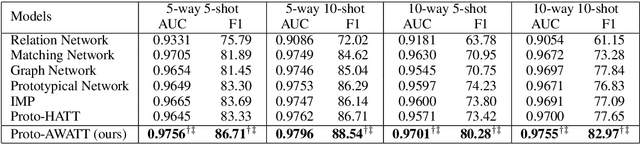
Aspect category detection (ACD) in sentiment analysis aims to identify the aspect categories mentioned in a sentence. In this paper, we formulate ACD in the few-shot learning scenario. However, existing few-shot learning approaches mainly focus on single-label predictions. These methods can not work well for the ACD task since a sentence may contain multiple aspect categories. Therefore, we propose a multi-label few-shot learning method based on the prototypical network. To alleviate the noise, we design two effective attention mechanisms. The support-set attention aims to extract better prototypes by removing irrelevant aspects. The query-set attention computes multiple prototype-specific representations for each query instance, which are then used to compute accurate distances with the corresponding prototypes. To achieve multi-label inference, we further learn a dynamic threshold per instance by a policy network. Extensive experimental results on three datasets demonstrate that the proposed method significantly outperforms strong baselines.
Learning to Detect Opinion Snippet for Aspect-Based Sentiment Analysis
Sep 25, 2019



Aspect-based sentiment analysis (ABSA) is to predict the sentiment polarity towards a particular aspect in a sentence. Recently, this task has been widely addressed by the neural attention mechanism, which computes attention weights to softly select words for generating aspect-specific sentence representations. The attention is expected to concentrate on opinion words for accurate sentiment prediction. However, attention is prone to be distracted by noisy or misleading words, or opinion words from other aspects. In this paper, we propose an alternative hard-selection approach, which determines the start and end positions of the opinion snippet, and selects the words between these two positions for sentiment prediction. Specifically, we learn deep associations between the sentence and aspect, and the long-term dependencies within the sentence by leveraging the pre-trained BERT model. We further detect the opinion snippet by self-critical reinforcement learning. Especially, experimental results demonstrate the effectiveness of our method and prove that our hard-selection approach outperforms soft-selection approaches when handling multi-aspect sentences.
Domain-Invariant Feature Distillation for Cross-Domain Sentiment Classification
Aug 24, 2019
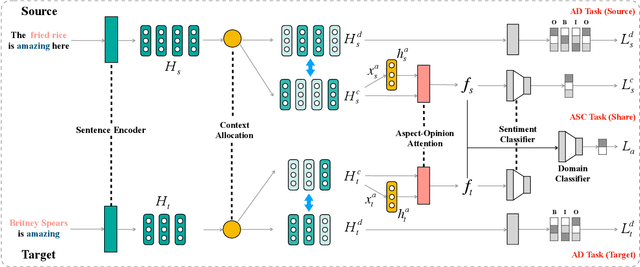
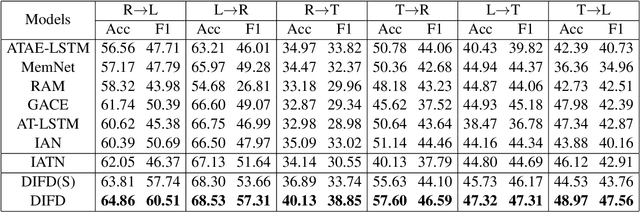
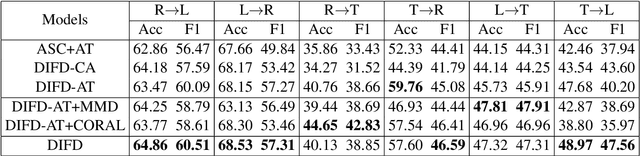
Cross-domain sentiment classification has drawn much attention in recent years. Most existing approaches focus on learning domain-invariant representations in both the source and target domains, while few of them pay attention to the domain-specific information. Despite the non-transferability of the domain-specific information, simultaneously learning domain-dependent representations can facilitate the learning of domain-invariant representations. In this paper, we focus on aspect-level cross-domain sentiment classification, and propose to distill the domain-invariant sentiment features with the help of an orthogonal domain-dependent task, i.e. aspect detection, which is built on the aspects varying widely in different domains. We conduct extensive experiments on three public datasets and the experimental results demonstrate the effectiveness of our method.