 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCA-NOC: Relative Contrastive Alignment for Novel Object Captioning
Dec 11, 2023
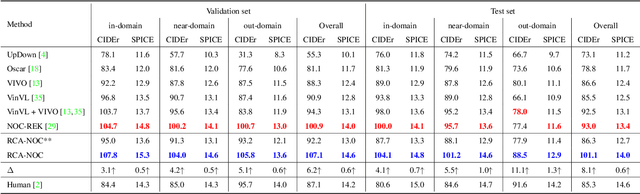
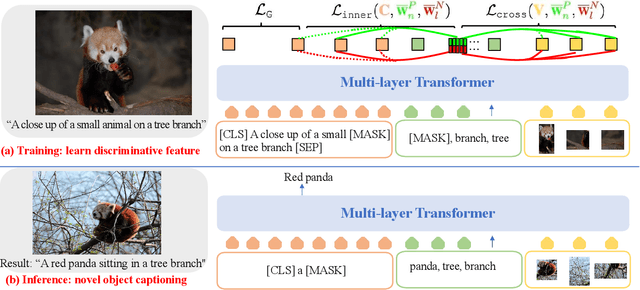

In this paper, we introduce a novel approach to novel object captioning which employs relative contrastive learning to learn visual and semantic alignment. Our approach maximizes compatibility between regions and object tags in a contrastive manner. To set up a proper contrastive learning objective, for each image, we augment tags by leveraging the relative nature of positive and negative pairs obtained from foundation models such as CLIP. We then use the rank of each augmented tag in a list as a relative relevance label to contrast each top-ranked tag with a set of lower-ranked tags. This learning objective encourages the top-ranked tags to be more compatible with their image and text context than lower-ranked tags, thus improving the discriminative ability of the learned multi-modality representation. We evaluate our approach on two datasets and show that our proposed RCA-NOC approach outperforms state-of-the-art methods by a large margin, demonstrating its effectiveness in improving vision-language representation for novel object captioning.
ClickSeg: 3D Instance Segmentation with Click-Level Weak Annotations
Jul 19, 2023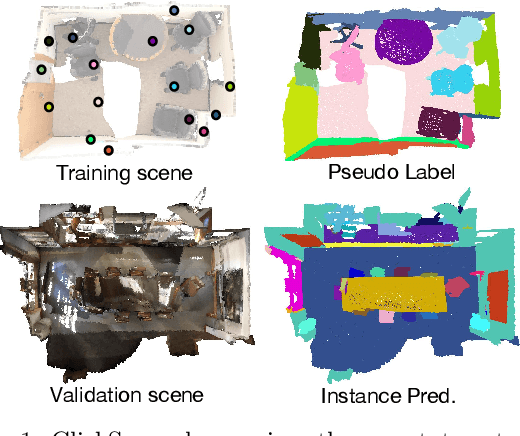

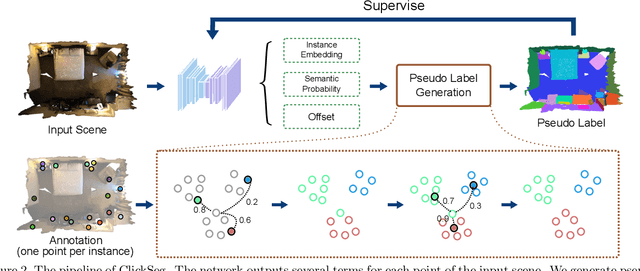

3D instance segmentation methods often require fully-annotated dense labels for training, which are costly to obtain. In this paper, we present ClickSeg, a novel click-level weakly supervised 3D instance segmentation method that requires one point per instance annotation merely. Such a problem is very challenging due to the extremely limited labels, which has rarely been solved before. We first develop a baseline weakly-supervised training method, which generates pseudo labels for unlabeled data by the model itself. To utilize the property of click-level annotation setting, we further propose a new training framework. Instead of directly using the model inference way, i.e., mean-shift clustering, to generate the pseudo labels, we propose to use k-means with fixed initial seeds: the annotated points. New similarity metrics are further designed for clustering. Experiments on ScanNetV2 and S3DIS datasets show that the proposed ClickSeg surpasses the previous best weakly supervised instance segmentation result by a large margin (e.g., +9.4% mAP on ScanNetV2). Using 0.02% supervision signals merely, ClickSeg achieves $\sim$90% of the accuracy of the fully-supervised counterpart. Meanwhile, it also achieves state-of-the-art semantic segmentation results among weakly supervised methods that use the same annotation settings.