 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Estimation in Data Streams: Learning the Optimal Hashing Scheme
Paper and Code
Jul 17, 2020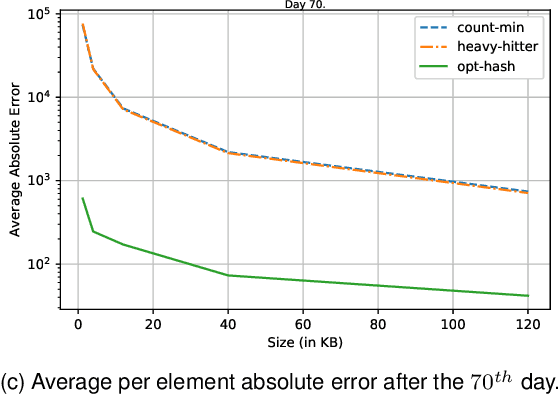
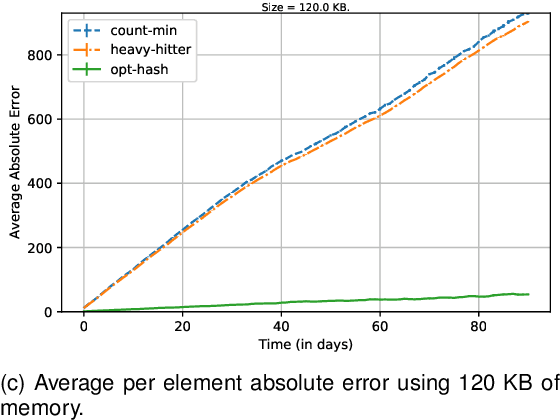
We present a novel approach for the problem of frequency estimation in data streams that is based on optimization and machine learning. Contrary to state-of-the-art streaming frequency estimation algorithms, which heavily rely on random hashing to maintain the frequency distribution of the data steam using limited storage, the proposed approach exploits an observed stream prefix to near-optimally hash elements and compress the target frequency distribution. We develop an exact mixed-integer linear optimization formulation, as well as an efficient block coordinate descent algorithm, that enable us to compute near-optimal hashing schemes for elements seen in the observed stream prefix; then, we use machine learning to hash unseen elements. We empirically evaluate the proposed approach on real-world search query data and show that it outperforms existing approaches by one to two orders of magnitude in terms of its average (per element) estimation error and by 45-90% in terms of its expected magnitude of estimation error.