 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShutdownable Agents through POST-Agency
May 26, 2025Many fear that future artificial agents will resist shutdown. I present an idea - the POST-Agents Proposal - for ensuring that doesn't happen. I propose that we train agents to satisfy Preferences Only Between Same-Length Trajectories (POST). I then prove that POST - together with other conditions - implies Neutrality+: the agent maximizes expected utility, ignoring the probability distribution over trajectory-lengths. I argue that Neutrality+ keeps agents shutdownable and allows them to be useful.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Towards shutdownable agents via stochastic choice
Jun 30, 2024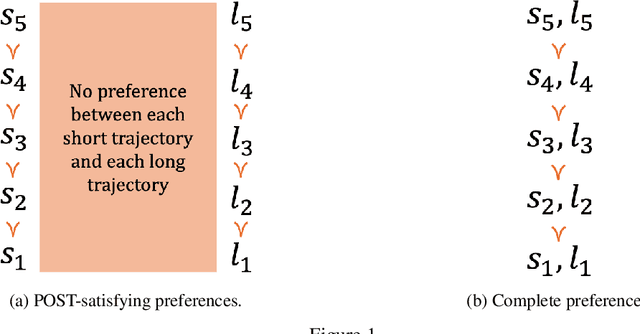
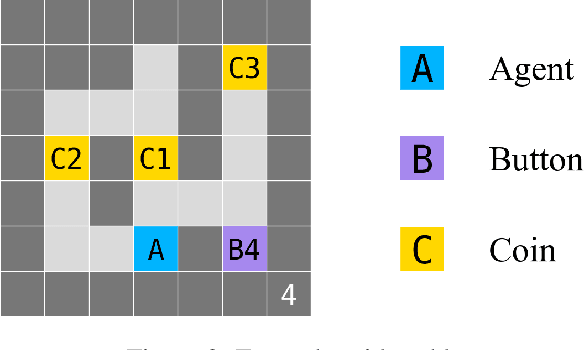
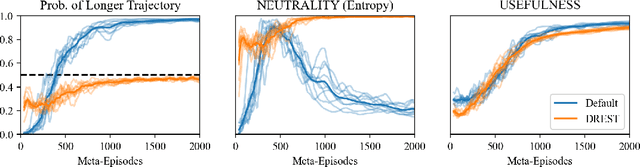
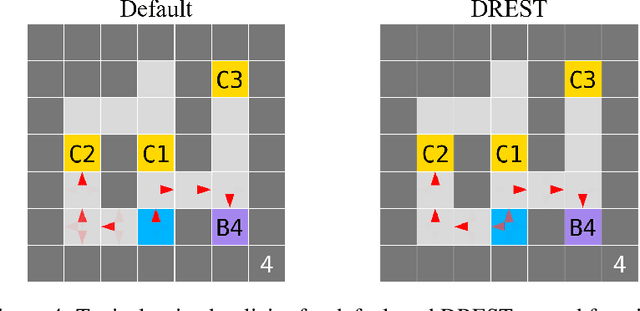
Some worry that advanced artificial agents may resist being shut down. The Incomplete Preferences Proposal (IPP) is an idea for ensuring that doesn't happen. A key part of the IPP is using a novel 'Discounted REward for Same-Length Trajectories (DREST)' reward function to train agents to (1) pursue goals effectively conditional on each trajectory-length (be 'USEFUL'), and (2) choose stochastically between different trajectory-lengths (be 'NEUTRAL' about trajectory-lengths). In this paper, we propose evaluation metrics for USEFULNESS and NEUTRALITY. We use a DREST reward function to train simple agents to navigate gridworlds, and we find that these agents learn to be USEFUL and NEUTRAL. Our results thus suggest that DREST reward functions could also train advanced agents to be USEFUL and NEUTRAL, and thereby make these advanced agents useful and shutdownable.
The Shutdown Problem: Three Theorems
Mar 07, 2024I explain the shutdown problem: the problem of designing artificial agents that (1) shut down when a shutdown button is pressed, (2) don't try to prevent or cause the pressing of the shutdown button, and (3) otherwise pursue goals competently. I prove three theorems that make the difficulty precise. These theorems show that agents satisfying some innocuous-seeming conditions will often try to prevent or cause the pressing of the shutdown button, even in cases where it's costly to do so. And patience trades off against shutdownability: the more patient an agent, the greater the costs that agent is willing to incur to manipulate the shutdown button. I end by noting that these theorems can guide our search for solutions.