 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunting for "Oddballs" with Machine Learning: Detecting Anomalous Exoplanets Using a Deep-Learned Low-Dimensional Representation of Transit Spectra with Autoencoders
Jan 05, 2026This study explores the application of autoencoder-based machine learning techniques for anomaly detection to identify exoplanet atmospheres with unconventional chemical signatures using a low-dimensional data representation. We use the Atmospheric Big Challenge (ABC) database, a publicly available dataset with over 100,000 simulated exoplanet spectra, to construct an anomaly detection scenario by defining CO2-rich atmospheres as anomalies and CO2-poor atmospheres as the normal class. We benchmarked four different anomaly detection strategies: Autoencoder Reconstruction Loss, One-Class Support Vector Machine (1 class-SVM), K-means Clustering, and Local Outlier Factor (LOF). Each method was evaluated in both the original spectral space and the autoencoder's latent space using Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) metrics. To test the performance of the different methods under realistic conditions, we introduced Gaussian noise levels ranging from 10 to 50 ppm. Our results indicate that anomaly detection is consistently more effective when performed within the latent space across all noise levels. Specifically, K-means clustering in the latent space emerged as a stable and high-performing method. We demonstrate that this anomaly detection approach is robust to noise levels up to 30 ppm (consistent with realistic space-based observations) and remains viable even at 50 ppm when leveraging latent space representations. On the other hand, the performance of the anomaly detection methods applied directly in the raw spectral space degrades significantly with increasing the level of noise. This suggests that autoencoder-driven dimensionality reduction offers a robust methodology for flagging chemically anomalous targets in large-scale surveys where exhaustive retrievals are computationally prohibitive.
Supervised Machine Learning Methods with Uncertainty Quantification for Exoplanet Atmospheric Retrievals from Transmission Spectroscopy
Aug 07, 2025Standard Bayesian retrievals for exoplanet atmospheric parameters from transmission spectroscopy, while well understood and widely used, are generally computationally expensive. In the era of the JWST and other upcoming observatories, machine learning approaches have emerged as viable alternatives that are both efficient and robust. In this paper we present a systematic study of several existing machine learning regression techniques and compare their performance for retrieving exoplanet atmospheric parameters from transmission spectra. We benchmark the performance of the different algorithms on the accuracy, precision, and speed. The regression methods tested here include partial least squares (PLS), support vector machines (SVM), k nearest neighbors (KNN), decision trees (DT), random forests (RF), voting (VOTE), stacking (STACK), and extreme gradient boosting (XGB). We also investigate the impact of different preprocessing methods of the training data on the model performance. We quantify the model uncertainties across the entire dynamical range of planetary parameters. The best performing combination of ML model and preprocessing scheme is validated on a the case study of JWST observation of WASP-39b.
Quantum Diffusion Model for Quark and Gluon Jet Generation
Dec 30, 2024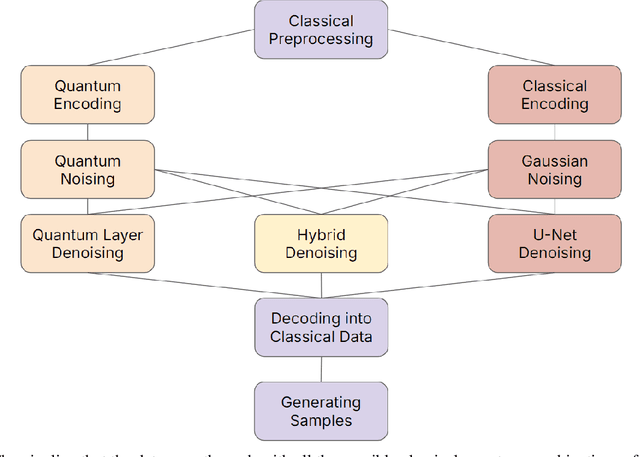

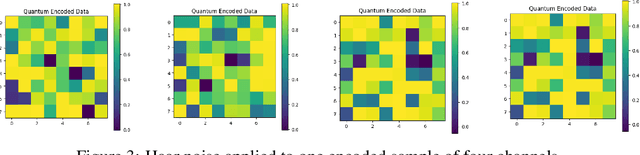
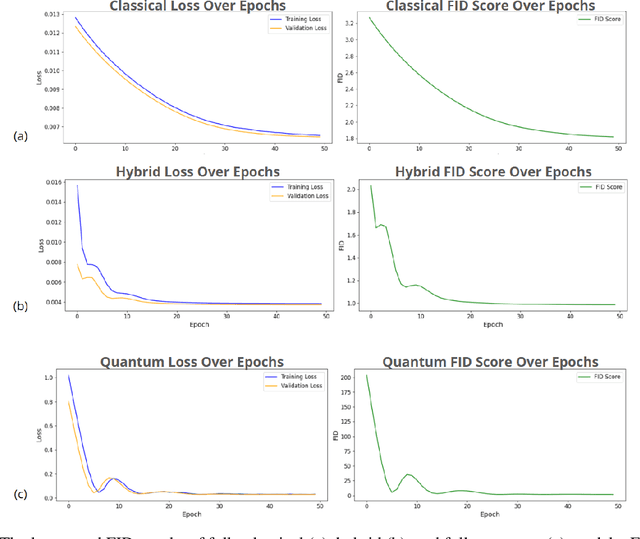
Diffusion models have demonstrated remarkable success in image generation, but they are computationally intensive and time-consuming to train. In this paper, we introduce a novel diffusion model that benefits from quantum computing techniques in order to mitigate computational challenges and enhance generative performance within high energy physics data. The fully quantum diffusion model replaces Gaussian noise with random unitary matrices in the forward process and incorporates a variational quantum circuit within the U-Net in the denoising architecture. We run evaluations on the structurally complex quark and gluon jets dataset from the Large Hadron Collider. The results demonstrate that the fully quantum and hybrid models are competitive with a similar classical model for jet generation, highlighting the potential of using quantum techniques for machine learning problems.
Lie-Equivariant Quantum Graph Neural Networks
Nov 22, 2024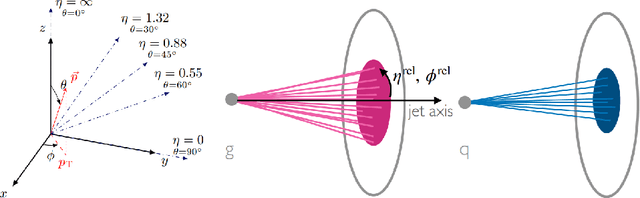

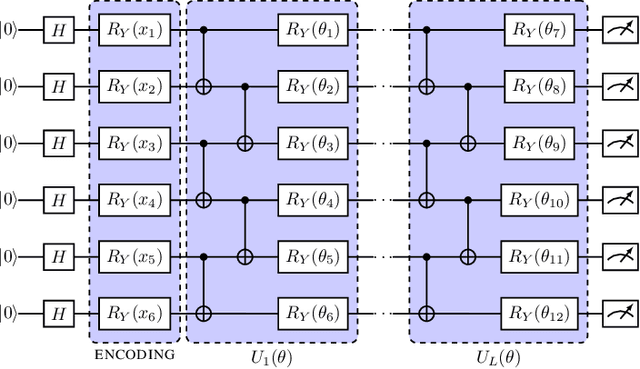
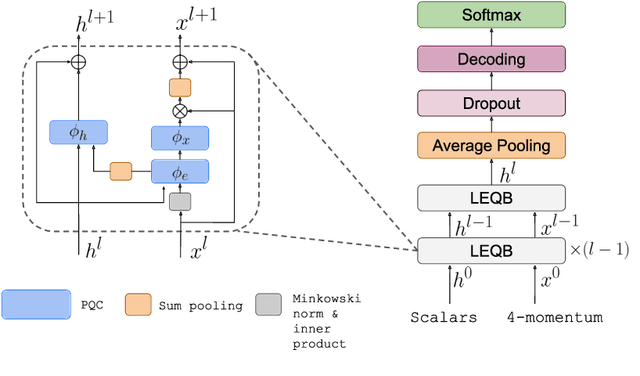
Discovering new phenomena at the Large Hadron Collider (LHC) involves the identification of rare signals over conventional backgrounds. Thus binary classification tasks are ubiquitous in analyses of the vast amounts of LHC data. We develop a Lie-Equivariant Quantum Graph Neural Network (Lie-EQGNN), a quantum model that is not only data efficient, but also has symmetry-preserving properties. Since Lorentz group equivariance has been shown to be beneficial for jet tagging, we build a Lorentz-equivariant quantum GNN for quark-gluon jet discrimination and show that its performance is on par with its classical state-of-the-art counterpart LorentzNet, making it a viable alternative to the conventional computing paradigm.
Quantum Attention for Vision Transformers in High Energy Physics
Nov 20, 2024We present a novel hybrid quantum-classical vision transformer architecture incorporating quantum orthogonal neural networks (QONNs) to enhance performance and computational efficiency in high-energy physics applications. Building on advancements in quantum vision transformers, our approach addresses limitations of prior models by leveraging the inherent advantages of QONNs, including stability and efficient parameterization in high-dimensional spaces. We evaluate the proposed architecture using multi-detector jet images from CMS Open Data, focusing on the task of distinguishing quark-initiated from gluon-initiated jets. The results indicate that embedding quantum orthogonal transformations within the attention mechanism can provide robust performance while offering promising scalability for machine learning challenges associated with the upcoming High Luminosity Large Hadron Collider. This work highlights the potential of quantum-enhanced models to address the computational demands of next-generation particle physics experiments.
Quantum Vision Transformers for Quark-Gluon Classification
May 16, 2024

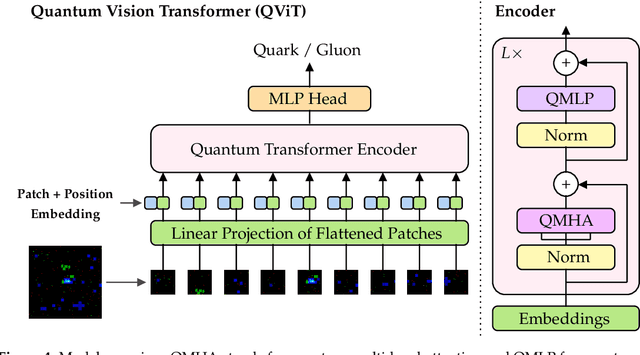
We introduce a hybrid quantum-classical vision transformer architecture, notable for its integration of variational quantum circuits within both the attention mechanism and the multi-layer perceptrons. The research addresses the critical challenge of computational efficiency and resource constraints in analyzing data from the upcoming High Luminosity Large Hadron Collider, presenting the architecture as a potential solution. In particular, we evaluate our method by applying the model to multi-detector jet images from CMS Open Data. The goal is to distinguish quark-initiated from gluon-initiated jets. We successfully train the quantum model and evaluate it via numerical simulations. Using this approach, we achieve classification performance almost on par with the one obtained with the completely classical architecture, considering a similar number of parameters.
* 14 pages, 8 figures. Published in MDPI Axioms 2024, 13(5), 323
Hybrid Quantum Vision Transformers for Event Classification in High Energy Physics
Feb 01, 2024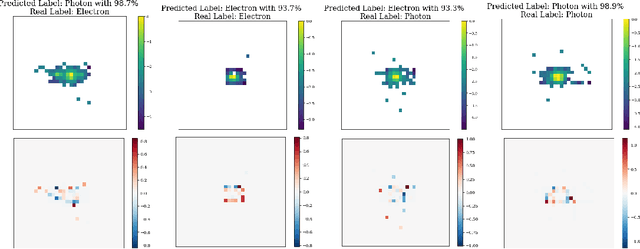
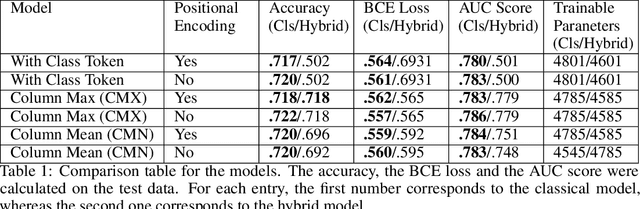
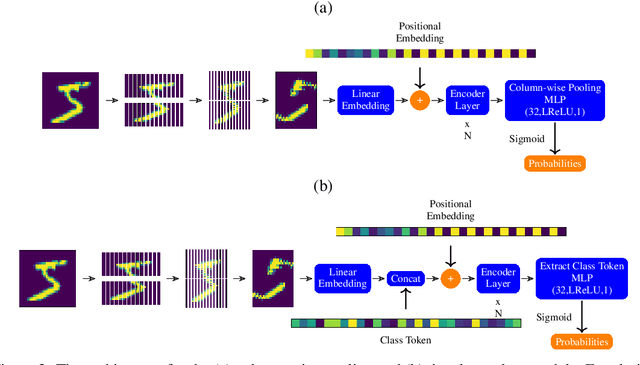
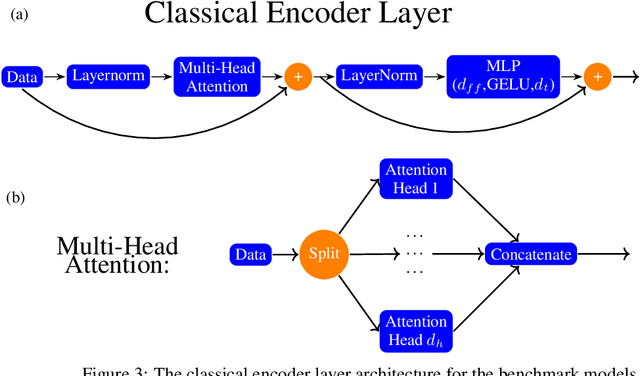
Models based on vision transformer architectures are considered state-of-the-art when it comes to image classification tasks. However, they require extensive computational resources both for training and deployment. The problem is exacerbated as the amount and complexity of the data increases. Quantum-based vision transformer models could potentially alleviate this issue by reducing the training and operating time while maintaining the same predictive power. Although current quantum computers are not yet able to perform high-dimensional tasks yet, they do offer one of the most efficient solutions for the future. In this work, we construct several variations of a quantum hybrid vision transformer for a classification problem in high energy physics (distinguishing photons and electrons in the electromagnetic calorimeter). We test them against classical vision transformer architectures. Our findings indicate that the hybrid models can achieve comparable performance to their classical analogues with a similar number of parameters.
Exploring the Truth and Beauty of Theory Landscapes with Machine Learning
Jan 21, 2024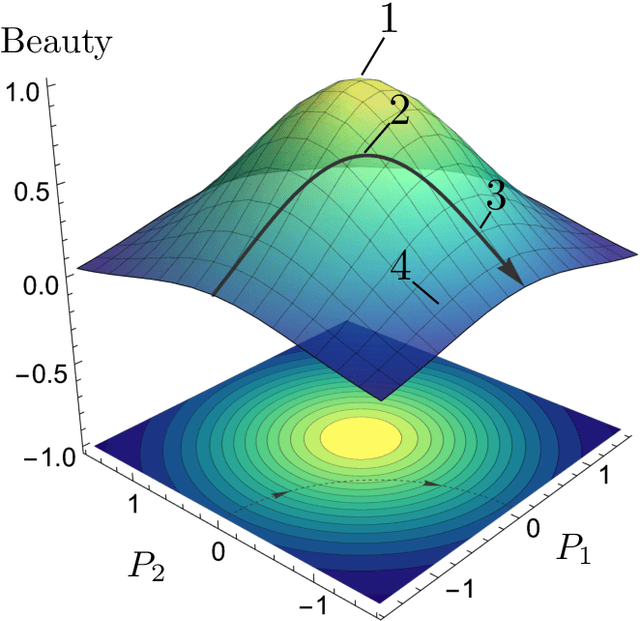

Theoretical physicists describe nature by i) building a theory model and ii) determining the model parameters. The latter step involves the dual aspect of both fitting to the existing experimental data and satisfying abstract criteria like beauty, naturalness, etc. We use the Yukawa quark sector as a toy example to demonstrate how both of those tasks can be accomplished with machine learning techniques. We propose loss functions whose minimization results in true models that are also beautiful as measured by three different criteria - uniformity, sparsity, or symmetry.
$\mathbb{Z}_2\times \mathbb{Z}_2$ Equivariant Quantum Neural Networks: Benchmarking against Classical Neural Networks
Nov 30, 2023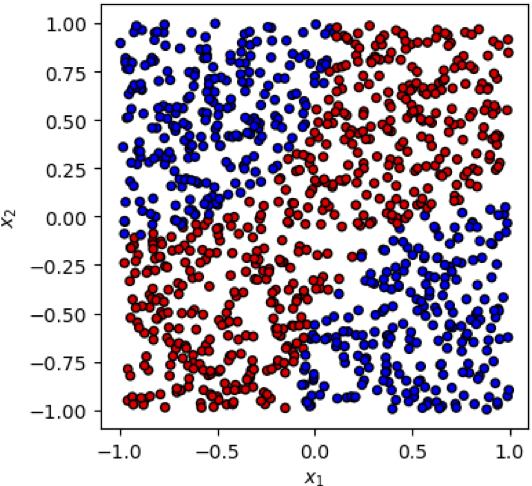
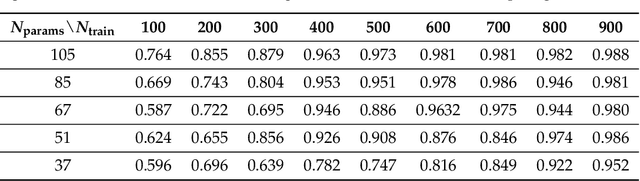
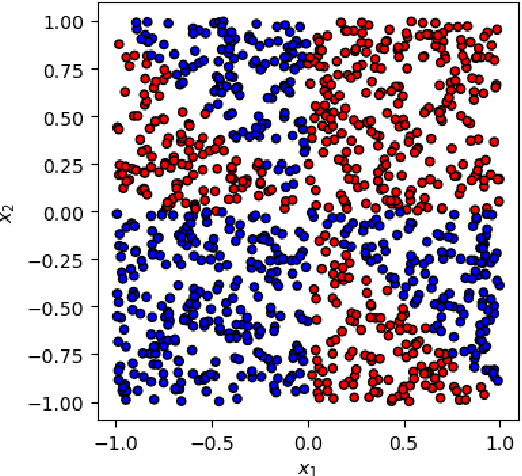
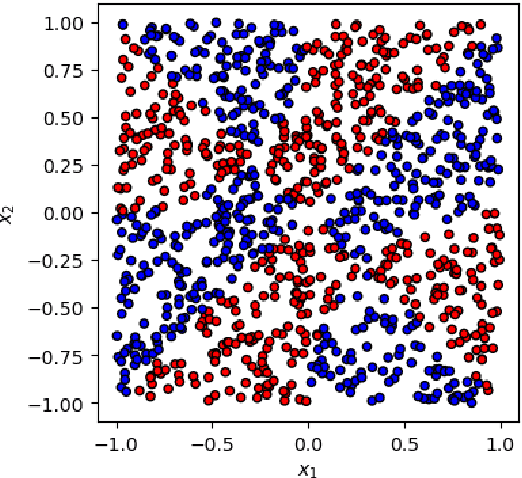
This paper presents a comprehensive comparative analysis of the performance of Equivariant Quantum Neural Networks (EQNN) and Quantum Neural Networks (QNN), juxtaposed against their classical counterparts: Equivariant Neural Networks (ENN) and Deep Neural Networks (DNN). We evaluate the performance of each network with two toy examples for a binary classification task, focusing on model complexity (measured by the number of parameters) and the size of the training data set. Our results show that the $\mathbb{Z}_2\times \mathbb{Z}_2$ EQNN and the QNN provide superior performance for smaller parameter sets and modest training data samples.
A Comparison Between Invariant and Equivariant Classical and Quantum Graph Neural Networks
Nov 30, 2023



Machine learning algorithms are heavily relied on to understand the vast amounts of data from high-energy particle collisions at the CERN Large Hadron Collider (LHC). The data from such collision events can naturally be represented with graph structures. Therefore, deep geometric methods, such as graph neural networks (GNNs), have been leveraged for various data analysis tasks in high-energy physics. One typical task is jet tagging, where jets are viewed as point clouds with distinct features and edge connections between their constituent particles. The increasing size and complexity of the LHC particle datasets, as well as the computational models used for their analysis, greatly motivate the development of alternative fast and efficient computational paradigms such as quantum computation. In addition, to enhance the validity and robustness of deep networks, one can leverage the fundamental symmetries present in the data through the use of invariant inputs and equivariant layers. In this paper, we perform a fair and comprehensive comparison between classical graph neural networks (GNNs) and equivariant graph neural networks (EGNNs) and their quantum counterparts: quantum graph neural networks (QGNNs) and equivariant quantum graph neural networks (EQGNN). The four architectures were benchmarked on a binary classification task to classify the parton-level particle initiating the jet. Based on their AUC scores, the quantum networks were shown to outperform the classical networks. However, seeing the computational advantage of the quantum networks in practice may have to wait for the further development of quantum technology and its associated APIs.