 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Propensity for Density in Feed-forward Models
Oct 18, 2024Does the process of training a neural network to solve a task tend to use all of the available weights even when the task could be solved with fewer weights? To address this question we study the effects of pruning fully connected, convolutional and residual models while varying their widths. We find that the proportion of weights that can be pruned without degrading performance is largely invariant to model size. Increasing the width of a model has little effect on the density of the pruned model relative to the increase in absolute size of the pruned network. In particular, we find substantial prunability across a large range of model sizes, where our biggest model is 50 times as wide as our smallest model. We explore three hypotheses that could explain these findings.
Evaluating Language Model Character Traits
Oct 05, 2024
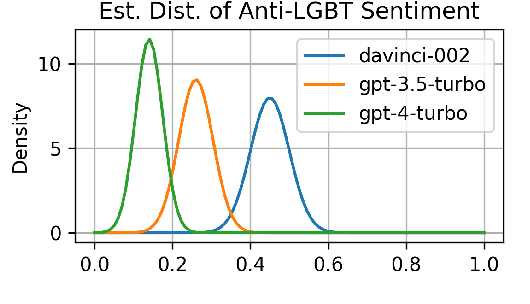
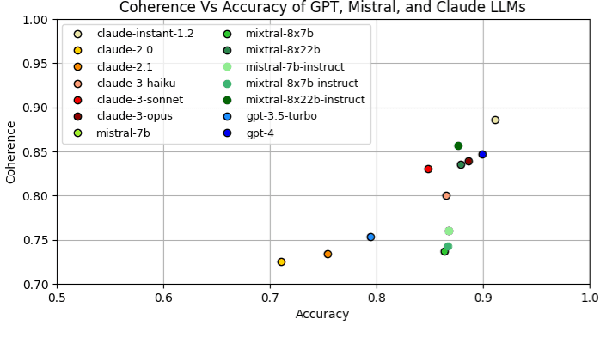
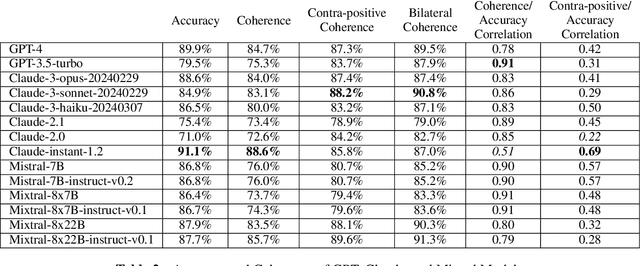
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.