 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Pathological Chain-of-Thought in Reasoning Models
Feb 14, 2026Chain-of-thought (CoT) reasoning is fundamental to modern LLM architectures and represents a critical intervention point for AI safety. However, CoT reasoning may exhibit failure modes that we note as pathologies, which prevent it from being useful for monitoring. Prior work has identified three distinct pathologies: post-hoc rationalization, where models generate plausible explanations backwards from predetermined answers; encoded reasoning, where intermediate steps conceal information within seemingly interpretable text; and internalized reasoning, where models replace explicit reasoning with meaningless filler tokens while computing internally. To better understand and discriminate between these pathologies, we create a set of concrete metrics that are simple to implement, computationally inexpensive, and task-agnostic. To validate our approach, we develop model organisms deliberately trained to exhibit specific CoT pathologies. Our work provides a practical toolkit for assessing CoT pathologies, with direct implications for training-time monitoring.
Representation Engineering for Large-Language Models: Survey and Research Challenges
Feb 24, 2025



Large-language models are capable of completing a variety of tasks, but remain unpredictable and intractable. Representation engineering seeks to resolve this problem through a new approach utilizing samples of contrasting inputs to detect and edit high-level representations of concepts such as honesty, harmfulness or power-seeking. We formalize the goals and methods of representation engineering to present a cohesive picture of work in this emerging discipline. We compare it with alternative approaches, such as mechanistic interpretability, prompt-engineering and fine-tuning. We outline risks such as performance decrease, compute time increases and steerability issues. We present a clear agenda for future research to build predictable, dynamic, safe and personalizable LLMs.
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
Can Safety Fine-Tuning Be More Principled? Lessons Learned from Cybersecurity
Jan 19, 2025As LLMs develop increasingly advanced capabilities, there is an increased need to minimize the harm that could be caused to society by certain model outputs; hence, most LLMs have safety guardrails added, for example via fine-tuning. In this paper, we argue the position that current safety fine-tuning is very similar to a traditional cat-and-mouse game (or arms race) between attackers and defenders in cybersecurity. Model jailbreaks and attacks are patched with bandaids to target the specific attack mechanism, but many similar attack vectors might remain. When defenders are not proactively coming up with principled mechanisms, it becomes very easy for attackers to sidestep any new defenses. We show how current defenses are insufficient to prevent new adversarial jailbreak attacks, reward hacking, and loss of control problems. In order to learn from past mistakes in cybersecurity, we draw analogies with historical examples and develop lessons learned that can be applied to LLM safety. These arguments support the need for new and more principled approaches to designing safe models, which are architected for security from the beginning. We describe several such approaches from the AI literature.
XDA: Accurate, Robust Disassembly with Transfer Learning
Oct 27, 2020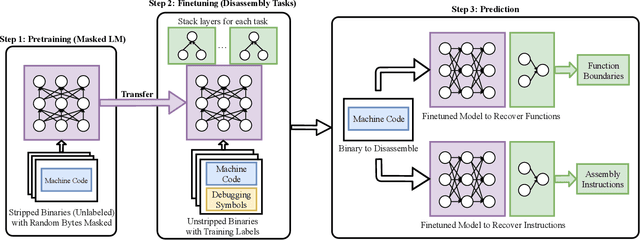
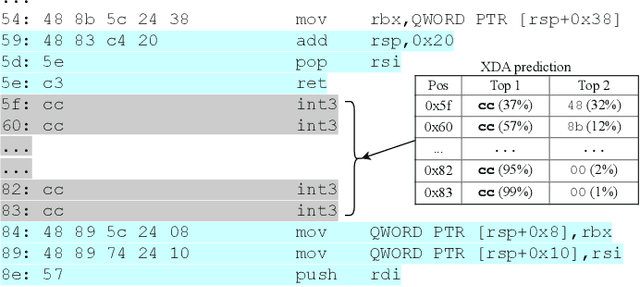
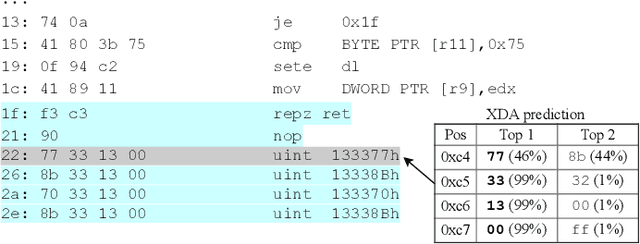
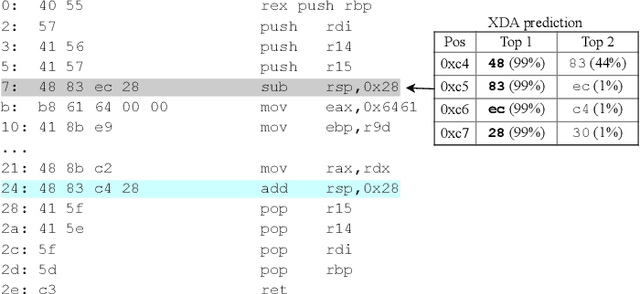
Accurate and robust disassembly of stripped binaries is challenging. The root of the difficulty is that high-level structures, such as instruction and function boundaries, are absent in stripped binaries and must be recovered based on incomplete information. Current disassembly approaches rely on heuristics or simple pattern matching to approximate the recovery, but these methods are often inaccurate and brittle, especially across different compiler optimizations. We present XDA, a transfer-learning-based disassembly framework that learns different contextual dependencies present in machine code and transfers this knowledge for accurate and robust disassembly. We design a self-supervised learning task motivated by masked Language Modeling to learn interactions among byte sequences in binaries. The outputs from this task are byte embeddings that encode sophisticated contextual dependencies between input binaries' byte tokens, which can then be finetuned for downstream disassembly tasks. We evaluate XDA's performance on two disassembly tasks, recovering function boundaries and assembly instructions, on a collection of 3,121 binaries taken from SPEC CPU2017, SPEC CPU2006, and the BAP corpus. The binaries are compiled by GCC, ICC, and MSVC on x86/x64 Windows and Linux platforms over 4 optimization levels. XDA achieves 99.0% and 99.7% F1 score at recovering function boundaries and instructions, respectively, surpassing the previous state-of-the-art on both tasks. It also maintains speed on par with the fastest ML-based approach and is up to 38x faster than hand-written disassemblers like IDA Pro.
Ensemble Model Patching: A Parameter-Efficient Variational Bayesian Neural Network
May 23, 2019
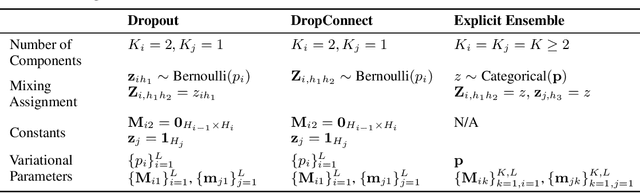


Two main obstacles preventing the widespread adoption of variational Bayesian neural networks are the high parameter overhead that makes them infeasible on large networks, and the difficulty of implementation, which can be thought of as "programming overhead." MC dropout [Gal and Ghahramani, 2016] is popular because it sidesteps these obstacles. Nevertheless, dropout is often harmful to model performance when used in networks with batch normalization layers [Li et al., 2018], which are an indispensable part of modern neural networks. We construct a general variational family for ensemble-based Bayesian neural networks that encompasses dropout as a special case. We further present two specific members of this family that work well with batch normalization layers, while retaining the benefits of low parameter and programming overhead, comparable to non-Bayesian training. Our proposed methods improve predictive accuracy and achieve almost perfect calibration on a ResNet-18 trained with ImageNet.