 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimitations of Agents Simulated by Predictive Models
Feb 08, 2024There is increasing focus on adapting predictive models into agent-like systems, most notably AI assistants based on language models. We outline two structural reasons for why these models can fail when turned into agents. First, we discuss auto-suggestive delusions. Prior work has shown theoretically that models fail to imitate agents that generated the training data if the agents relied on hidden observations: the hidden observations act as confounding variables, and the models treat actions they generate as evidence for nonexistent observations. Second, we introduce and formally study a related, novel limitation: predictor-policy incoherence. When a model generates a sequence of actions, the model's implicit prediction of the policy that generated those actions can serve as a confounding variable. The result is that models choose actions as if they expect future actions to be suboptimal, causing them to be overly conservative. We show that both of those failures are fixed by including a feedback loop from the environment, that is, re-training the models on their own actions. We give simple demonstrations of both limitations using Decision Transformers and confirm that empirical results agree with our conceptual and formal analysis. Our treatment provides a unifying view of those failure modes, and informs the question of why fine-tuning offline learned policies with online learning makes them more effective.
Choose Your Own Question: Encouraging Self-Personalization in Learning Path Construction
May 08, 2020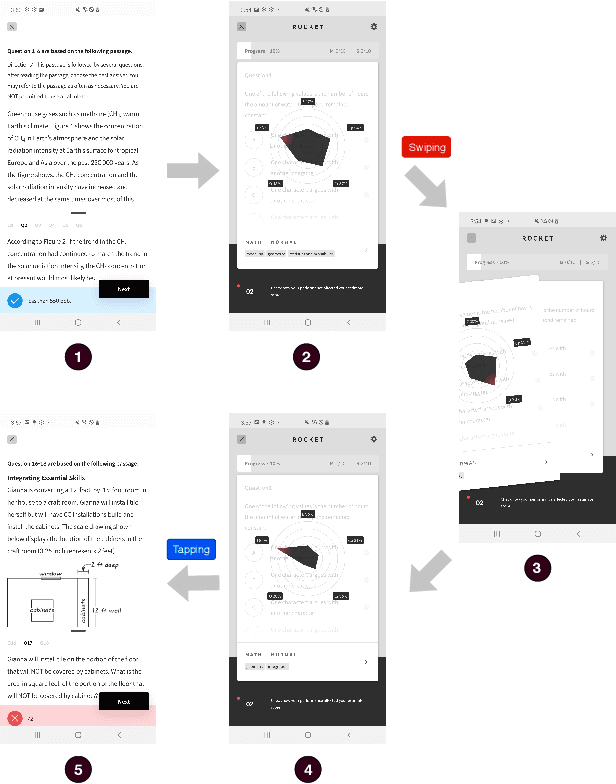
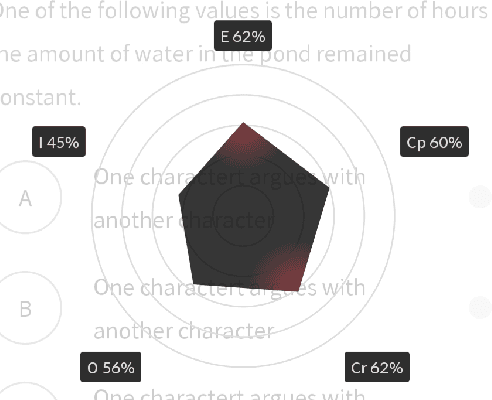
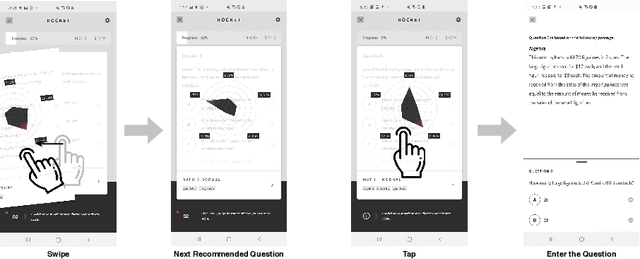
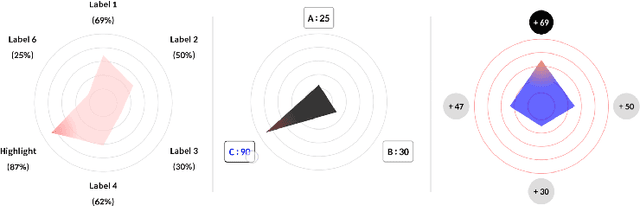
Learning Path Recommendation is the heart of adaptive learning, the educational paradigm of an Interactive Educational System (IES) providing a personalized learning experience based on the student's history of learning activities. In typical existing IESs, the student must fully consume a recommended learning item to be provided a new recommendation. This workflow comes with several limitations. For example, there is no opportunity for the student to give feedback on the choice of learning items made by the IES. Furthermore, the mechanism by which the choice is made is opaque to the student, limiting the student's ability to track their learning. To this end, we introduce Rocket, a Tinder-like User Interface for a general class of IESs. Rocket provides a visual representation of Artificial Intelligence (AI)-extracted features of learning materials, allowing the student to quickly decide whether the material meets their needs. The student can choose between engaging with the material and receiving a new recommendation by swiping or tapping. Rocket offers the following potential improvements for IES User Interfaces: First, Rocket enhances the explainability of IES recommendations by showing students a visual summary of the meaningful AI-extracted features used in the decision-making process. Second, Rocket enables self-personalization of the learning experience by leveraging the students' knowledge of their own abilities and needs. Finally, Rocket provides students with fine-grained information on their learning path, giving them an avenue to assess their own skills and track their learning progress. We present the source code of Rocket, in which we emphasize the independence and extensibility of each component, and make it publicly available for all purposes.
Towards an Appropriate Query, Key, and Value Computation for Knowledge Tracing
Feb 14, 2020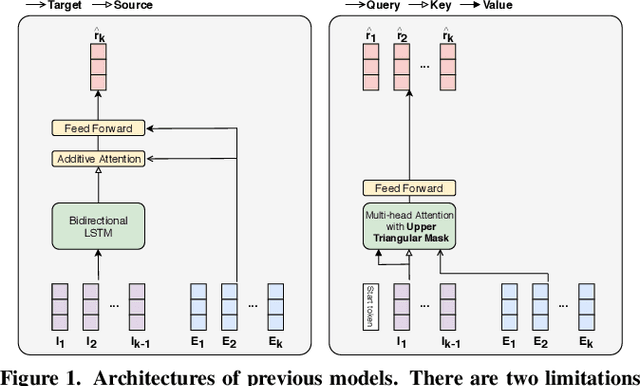
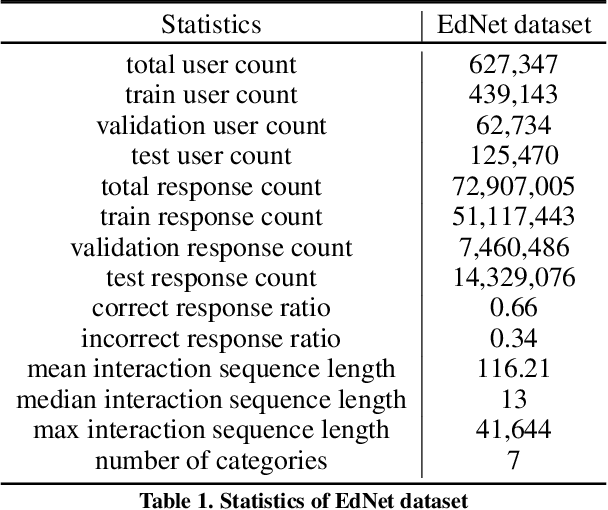
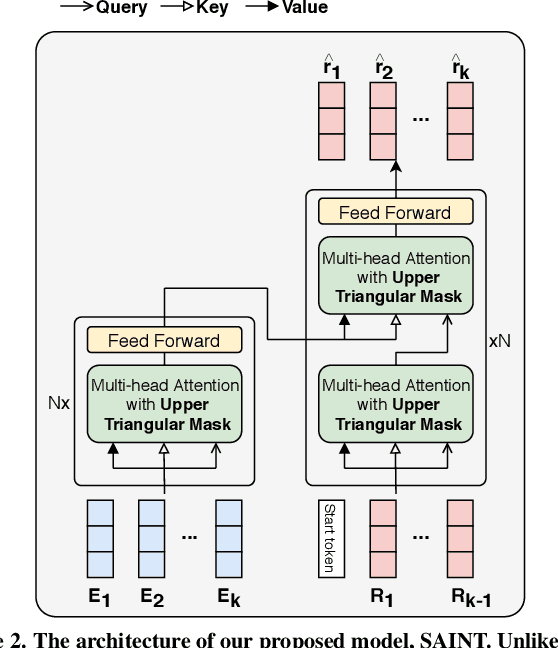
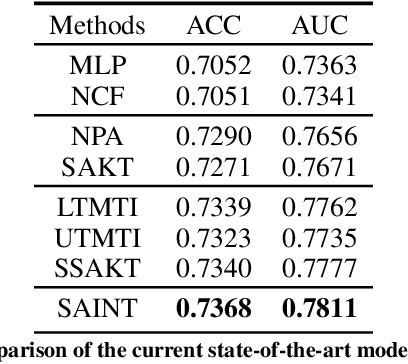
Knowledge tracing, the act of modeling a student's knowledge through learning activities, is an extensively studied problem in the field of computer-aided education. Although models with attention mechanism have outperformed traditional approaches such as Bayesian knowledge tracing and collaborative filtering, they share two limitations. Firstly, the models rely on shallow attention layers and fail to capture complex relations among exercises and responses over time. Secondly, different combinations of queries, keys and values for the self-attention layer for knowledge tracing were not extensively explored. Usual practice of using exercises and interactions (exercise-response pairs) as queries and keys/values respectively lacks empirical support. In this paper, we propose a novel Transformer based model for knowledge tracing, SAINT: Separated Self-AttentIve Neural Knowledge Tracing. SAINT has an encoder-decoder structure where exercise and response embedding sequence separately enter the encoder and the decoder respectively, which allows to stack attention layers multiple times. To the best of our knowledge, this is the first work to suggest an encoder-decoder model for knowledge tracing that applies deep self-attentive layers to exercises and responses separately. The empirical evaluations on a large-scale knowledge tracing dataset show that SAINT achieves the state-of-the-art performance in knowledge tracing with the improvement of AUC by 1.8% compared to the current state-of-the-art models.