 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge75 Languages, 1 Model: Parsing Universal Dependencies Universally
Apr 05, 2019



We present UDify, a multilingual multi-task model capable of accurately predicting universal part-of-speech, morphological features, lemmas, and dependency trees simultaneously for all 124 Universal Dependencies treebanks across 75 languages. By leveraging a multilingual BERT self-attention model pretrained on 104 languages, we found that fine-tuning it on all datasets concatenated together with simple softmax classifiers for each UD task can result in state-of-the-art UPOS, UFeats, Lemmas, UAS, and LAS scores, without requiring any recurrent or language-specific components. We evaluate UDify for multilingual learning, showing that low-resource languages benefit the most from cross-linguistic annotations. We also evaluate for zero-shot learning, with results suggesting that multilingual training provides strong UD predictions even for languages that neither UDify nor BERT have ever been trained on. Code for UDify is available at https://github.com/hyperparticle/udify.
LemmaTag: Jointly Tagging and Lemmatizing for Morphologically-Rich Languages with BRNNs
Aug 27, 2018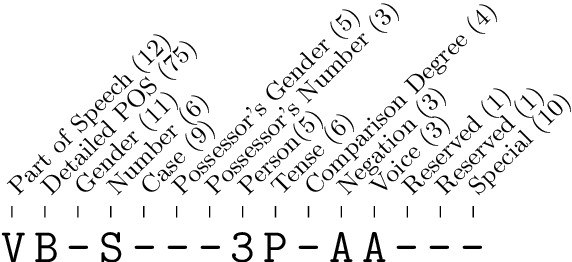

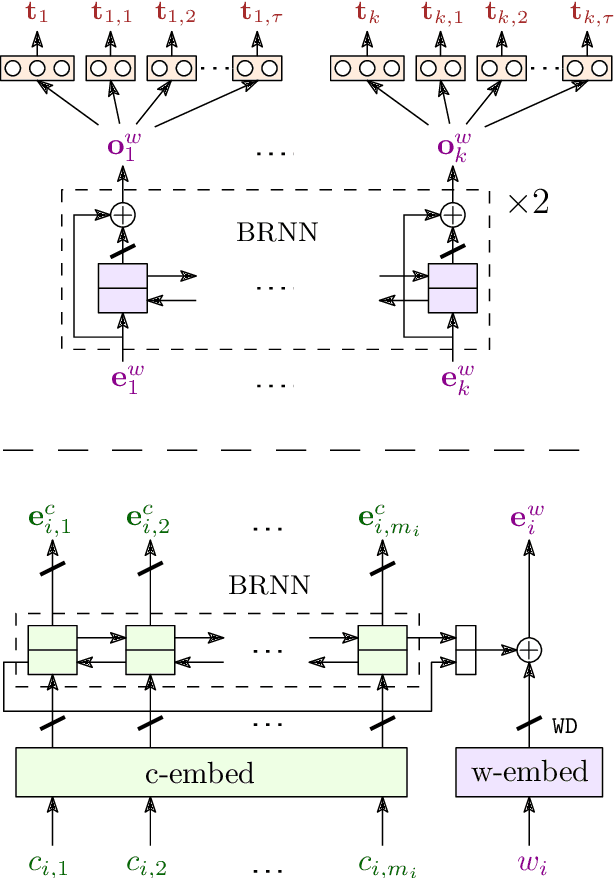
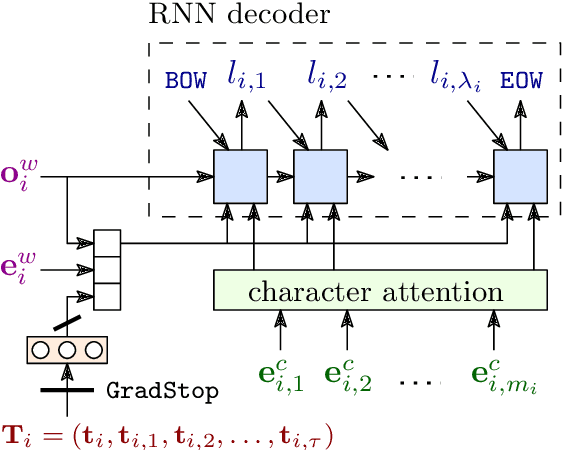
We present LemmaTag, a featureless neural network architecture that jointly generates part-of-speech tags and lemmas for sentences by using bidirectional RNNs with character-level and word-level embeddings. We demonstrate that both tasks benefit from sharing the encoding part of the network, predicting tag subcategories, and using the tagger output as an input to the lemmatizer. We evaluate our model across several languages with complex morphology, which surpasses state-of-the-art accuracy in both part-of-speech tagging and lemmatization in Czech, German, and Arabic.