 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Identity of Distributions under Kolmogorov Distance in Polylogarithmic Space
Oct 29, 2024Suppose we have a sample from a distribution $D$ and we want to test whether $D = D^*$ for a fixed distribution $D^*$. Specifically, we want to reject with constant probability, if the distance of $D$ from $D^*$ is $\geq \varepsilon$ in a given metric. In the case of continuous distributions, this has been studied thoroughly in the statistics literature. Namely, for the well-studied Kolmogorov metric a test is known that uses the optimal $O(1/\varepsilon^2)$ samples. However, this test naively uses also space $O(1/\varepsilon^2)$, and previous work improved this to $O(1/\varepsilon)$. In this paper, we show that much less space suffices -- we give an algorithm that uses space $O(\log^4 \varepsilon^{-1})$ in the streaming setting while also using an asymptotically optimal number of samples. This is in contrast with the standard total variation distance on discrete distributions for which such space reduction is known to be impossible. Finally, we state 9 related open problems that we hope will spark interest in this and related problems.
Better Differentially Private Approximate Histograms and Heavy Hitters using the Misra-Gries Sketch
Jan 06, 2023We consider the problem of computing differentially private approximate histograms and heavy hitters in a stream of elements. In the non-private setting, this is often done using the sketch of Misra and Gries [Science of Computer Programming, 1982]. Chan, Li, Shi, and Xu [PETS 2012] describe a differentially private version of the Misra-Gries sketch, but the amount of noise it adds can be large and scales linearly with the size of the sketch: the more accurate the sketch is, the more noise this approach has to add. We present a better mechanism for releasing Misra-Gries sketch under $(\varepsilon,\delta)$-differential privacy. It adds noise with magnitude independent of the size of the sketch size, in fact, the maximum error coming from the noise is the same as the best known in the private non-streaming setting, up to a constant factor. Our mechanism is simple and likely to be practical. We also give a simple post-processing step of the Misra-Gries sketch that does not increase the worst-case error guarantee. It is sufficient to add noise to this new sketch with less than twice the magnitude of the non-streaming setting. This improves on the previous result for $\varepsilon$-differential privacy where the noise scales linearly to the size of the sketch.
A Nearly Tight Analysis of Greedy k-means++
Jul 16, 2022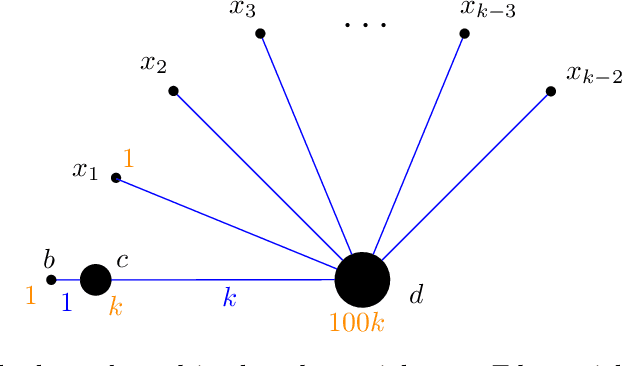
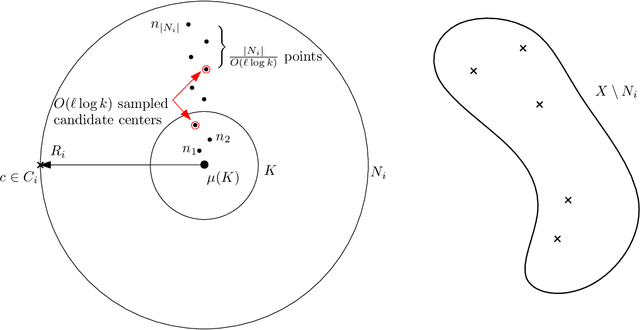

The famous $k$-means++ algorithm of Arthur and Vassilvitskii [SODA 2007] is the most popular way of solving the $k$-means problem in practice. The algorithm is very simple: it samples the first center uniformly at random and each of the following $k-1$ centers is then always sampled proportional to its squared distance to the closest center so far. Afterward, Lloyd's iterative algorithm is run. The $k$-means++ algorithm is known to return a $\Theta(\log k)$ approximate solution in expectation. In their seminal work, Arthur and Vassilvitskii [SODA 2007] asked about the guarantees for its following \emph{greedy} variant: in every step, we sample $\ell$ candidate centers instead of one and then pick the one that minimizes the new cost. This is also how $k$-means++ is implemented in e.g. the popular Scikit-learn library [Pedregosa et al.; JMLR 2011]. We present nearly matching lower and upper bounds for the greedy $k$-means++: We prove that it is an $O(\ell^3 \log^3 k)$-approximation algorithm. On the other hand, we prove a lower bound of $\Omega(\ell^3 \log^3 k / \log^2(\ell\log k))$. Previously, only an $\Omega(\ell \log k)$ lower bound was known [Bhattacharya, Eube, R\"oglin, Schmidt; ESA 2020] and there was no known upper bound.
CountSketches, Feature Hashing and the Median of Three
Feb 03, 2021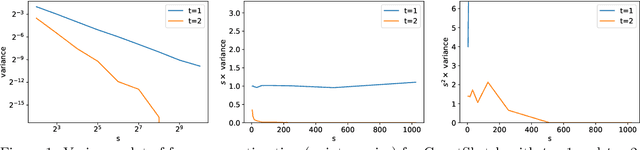
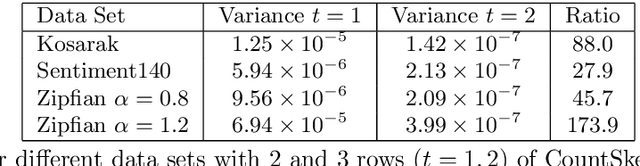
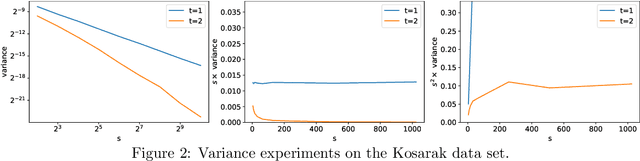
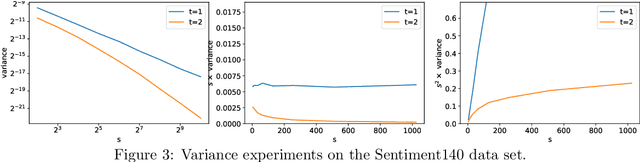
In this paper, we revisit the classic CountSketch method, which is a sparse, random projection that transforms a (high-dimensional) Euclidean vector $v$ to a vector of dimension $(2t-1) s$, where $t, s > 0$ are integer parameters. It is known that even for $t=1$, a CountSketch allows estimating coordinates of $v$ with variance bounded by $\|v\|_2^2/s$. For $t > 1$, the estimator takes the median of $2t-1$ independent estimates, and the probability that the estimate is off by more than $2 \|v\|_2/\sqrt{s}$ is exponentially small in $t$. This suggests choosing $t$ to be logarithmic in a desired inverse failure probability. However, implementations of CountSketch often use a small, constant $t$. Previous work only predicts a constant factor improvement in this setting. Our main contribution is a new analysis of Count-Sketch, showing an improvement in variance to $O(\min\{\|v\|_1^2/s^2,\|v\|_2^2/s\})$ when $t > 1$. That is, the variance decreases proportionally to $s^{-2}$, asymptotically for large enough $s$. We also study the variance in the setting where an inner product is to be estimated from two CountSketches. This finding suggests that the Feature Hashing method, which is essentially identical to CountSketch but does not make use of the median estimator, can be made more reliable at a small cost in settings where using a median estimator is possible. We confirm our theoretical findings in experiments and thereby help justify why a small constant number of estimates often suffice in practice. Our improved variance bounds are based on new general theorems about the variance and higher moments of the median of i.i.d. random variables that may be of independent interest.
Performance of Bounded-Rational Agents With the Ability to Self-Modify
Nov 12, 2020Self-modification of agents embedded in complex environments is hard to avoid, whether it happens via direct means (e.g. own code modification) or indirectly (e.g. influencing the operator, exploiting bugs or the environment). While it has been argued that intelligent agents have an incentive to avoid modifying their utility function so that their future instances will work towards the same goals, it is not clear whether this also applies in non-dualistic scenarios, where the agent is embedded in the environment. The problem of self-modification safety is raised by Bostrom in Superintelligence (2014) in the context of safe AGI deployment. In contrast to Everitt et al. (2016), who formally show that providing an option to self-modify is harmless for perfectly rational agents, we show that for agents with bounded rationality, self-modification may cause exponential deterioration in performance and gradual misalignment of a previously aligned agent. We investigate how the size of this effect depends on the type and magnitude of imperfections in the agent's rationality (1-4 below). We also discuss model assumptions and the wider problem and framing space. Specifically, we introduce several types of a bounded-rational agent, which either (1) doesn't always choose the optimal action, (2) is not perfectly aligned with human values, (3) has an innacurate model of the environment, or (4) uses the wrong temporal discounting factor. We show that while in the cases (2)-(4) the misalignment caused by the agent's imperfection does not worsen over time, with (1) the misalignment may grow exponentially.