 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountSketches, Feature Hashing and the Median of Three
Paper and Code
Feb 03, 2021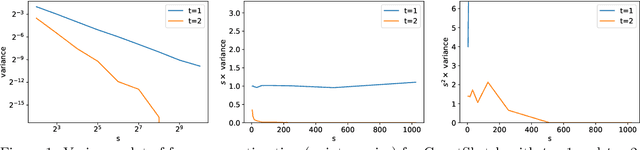
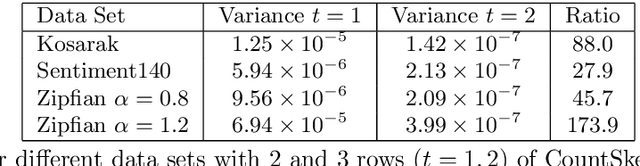
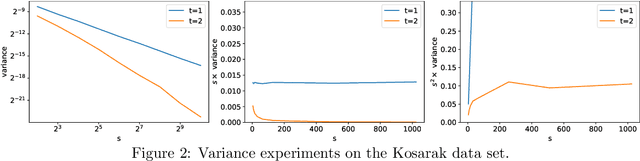
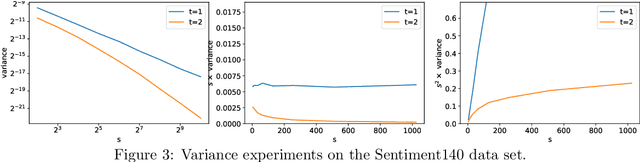
In this paper, we revisit the classic CountSketch method, which is a sparse, random projection that transforms a (high-dimensional) Euclidean vector $v$ to a vector of dimension $(2t-1) s$, where $t, s > 0$ are integer parameters. It is known that even for $t=1$, a CountSketch allows estimating coordinates of $v$ with variance bounded by $\|v\|_2^2/s$. For $t > 1$, the estimator takes the median of $2t-1$ independent estimates, and the probability that the estimate is off by more than $2 \|v\|_2/\sqrt{s}$ is exponentially small in $t$. This suggests choosing $t$ to be logarithmic in a desired inverse failure probability. However, implementations of CountSketch often use a small, constant $t$. Previous work only predicts a constant factor improvement in this setting. Our main contribution is a new analysis of Count-Sketch, showing an improvement in variance to $O(\min\{\|v\|_1^2/s^2,\|v\|_2^2/s\})$ when $t > 1$. That is, the variance decreases proportionally to $s^{-2}$, asymptotically for large enough $s$. We also study the variance in the setting where an inner product is to be estimated from two CountSketches. This finding suggests that the Feature Hashing method, which is essentially identical to CountSketch but does not make use of the median estimator, can be made more reliable at a small cost in settings where using a median estimator is possible. We confirm our theoretical findings in experiments and thereby help justify why a small constant number of estimates often suffice in practice. Our improved variance bounds are based on new general theorems about the variance and higher moments of the median of i.i.d. random variables that may be of independent interest.