 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Nearly Tight Analysis of Greedy k-means++
Jul 16, 2022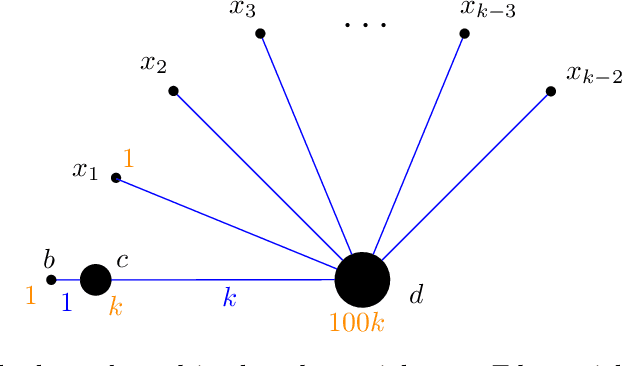

The famous $k$-means++ algorithm of Arthur and Vassilvitskii [SODA 2007] is the most popular way of solving the $k$-means problem in practice. The algorithm is very simple: it samples the first center uniformly at random and each of the following $k-1$ centers is then always sampled proportional to its squared distance to the closest center so far. Afterward, Lloyd's iterative algorithm is run. The $k$-means++ algorithm is known to return a $\Theta(\log k)$ approximate solution in expectation. In their seminal work, Arthur and Vassilvitskii [SODA 2007] asked about the guarantees for its following \emph{greedy} variant: in every step, we sample $\ell$ candidate centers instead of one and then pick the one that minimizes the new cost. This is also how $k$-means++ is implemented in e.g. the popular Scikit-learn library [Pedregosa et al.; JMLR 2011]. We present nearly matching lower and upper bounds for the greedy $k$-means++: We prove that it is an $O(\ell^3 \log^3 k)$-approximation algorithm. On the other hand, we prove a lower bound of $\Omega(\ell^3 \log^3 k / \log^2(\ell\log k))$. Previously, only an $\Omega(\ell \log k)$ lower bound was known [Bhattacharya, Eube, R\"oglin, Schmidt; ESA 2020] and there was no known upper bound.
Adapting $k$-means algorithms for outliers
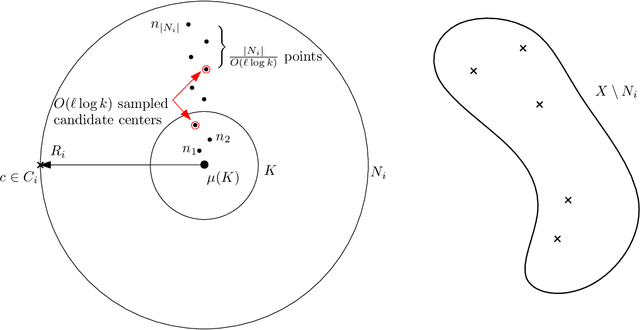
Jul 02, 2020

This paper shows how to adapt several simple and classical sampling-based algorithms for the $k$-means problem to the setting with outliers. Recently, Bhaskara et al. (NeurIPS 2019) showed how to adapt the classical $k$-means++ algorithm to the setting with outliers. However, their algorithm needs to output $O(\log (k) \cdot z)$ outliers, where $z$ is the number of true outliers, to match the $O(\log k)$-approximation guarantee of $k$-means++. In this paper, we build on their ideas and show how to adapt several sequential and distributed $k$-means algorithms to the setting with outliers, but with substantially stronger theoretical guarantees: our algorithms output $(1+\varepsilon)z$ outliers while achieving an $O(1 / \varepsilon)$-approximation to the objective function. In the sequential world, we achieve this by adapting a recent algorithm of Lattanzi and Sohler (ICML 2019). In the distributed setting, we adapt a simple algorithm of Guha et al. (IEEE Trans. Know. and Data Engineering 2003) and the popular $k$-means$\|$ of Bahmani et al. (PVLDB 2012). A theoretical application of our techniques is an algorithm with running time $\tilde{O}(nk^2/z)$ that achieves an $O(1)$-approximation to the objective function while outputting $O(z)$ outliers, assuming $k \ll z \ll n$. This is complemented with a matching lower bound of $\Omega(nk^2/z)$ for this problem in the oracle model.
k-means++: few more steps yield constant approximation
Feb 18, 2020

The k-means++ algorithm of Arthur and Vassilvitskii (SODA 2007) is a state-of-the-art algorithm for solving the k-means clustering problem and is known to give an O(log k)-approximation in expectation. Recently, Lattanzi and Sohler (ICML 2019) proposed augmenting k-means++ with O(k log log k) local search steps to yield a constant approximation (in expectation) to the k-means clustering problem. In this paper, we improve their analysis to show that, for any arbitrarily small constant $\eps > 0$, with only $\eps k$ additional local search steps, one can achieve a constant approximation guarantee (with high probability in k), resolving an open problem in their paper.