 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling the Dilemma of AI Errors: Exploring the Effectiveness of Human and Machine Explanations for Large Language Models
Paper and Code
Apr 11, 2024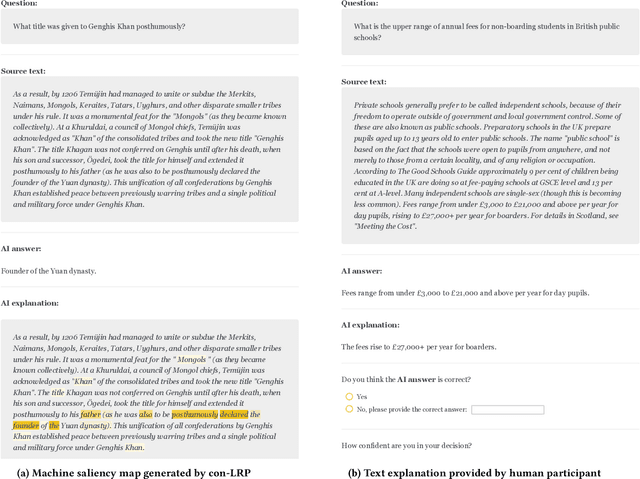

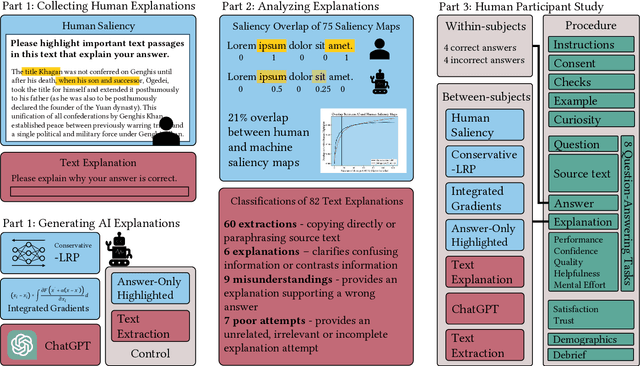
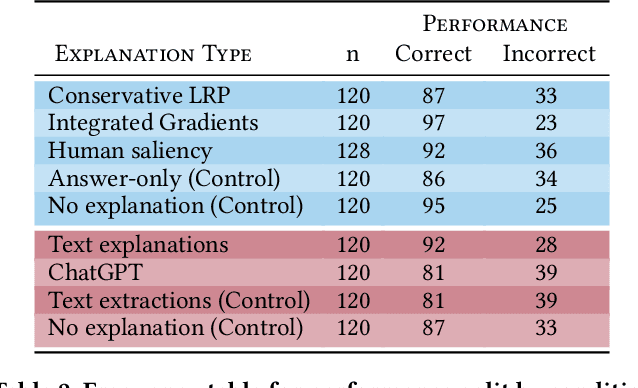
The field of eXplainable artificial intelligence (XAI) has produced a plethora of methods (e.g., saliency-maps) to gain insight into artificial intelligence (AI) models, and has exploded with the rise of deep learning (DL). However, human-participant studies question the efficacy of these methods, particularly when the AI output is wrong. In this study, we collected and analyzed 156 human-generated text and saliency-based explanations collected in a question-answering task (N=40) and compared them empirically to state-of-the-art XAI explanations (integrated gradients, conservative LRP, and ChatGPT) in a human-participant study (N=136). Our findings show that participants found human saliency maps to be more helpful in explaining AI answers than machine saliency maps, but performance negatively correlated with trust in the AI model and explanations. This finding hints at the dilemma of AI errors in explanation, where helpful explanations can lead to lower task performance when they support wrong AI predictions.