 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Better Understanding of Learning with Multiagent Teams
Jun 28, 2023While it has long been recognized that a team of individual learning agents can be greater than the sum of its parts, recent work has shown that larger teams are not necessarily more effective than smaller ones. In this paper, we study why and under which conditions certain team structures promote effective learning for a population of individual learning agents. We show that, depending on the environment, some team structures help agents learn to specialize into specific roles, resulting in more favorable global results. However, large teams create credit assignment challenges that reduce coordination, leading to large teams performing poorly compared to smaller ones. We support our conclusions with both theoretical analysis and empirical results.
Exploring the Benefits of Teams in Multiagent Learning
May 04, 2022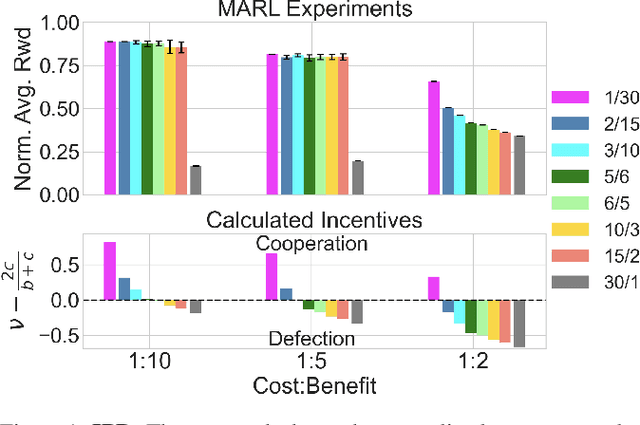
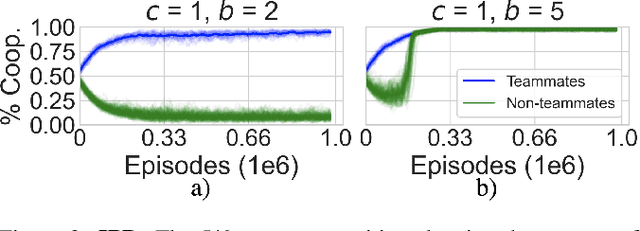
For problems requiring cooperation, many multiagent systems implement solutions among either individual agents or across an entire population towards a common goal. Multiagent teams are primarily studied when in conflict; however, organizational psychology (OP) highlights the benefits of teams among human populations for learning how to coordinate and cooperate. In this paper, we propose a new model of multiagent teams for reinforcement learning (RL) agents inspired by OP and early work on teams in artificial intelligence. We validate our model using complex social dilemmas that are popular in recent multiagent RL and find that agents divided into teams develop cooperative pro-social policies despite incentives to not cooperate. Furthermore, agents are better able to coordinate and learn emergent roles within their teams and achieve higher rewards compared to when the interests of all agents are aligned.
The Importance of Credo in Multiagent Learning
Apr 15, 2022
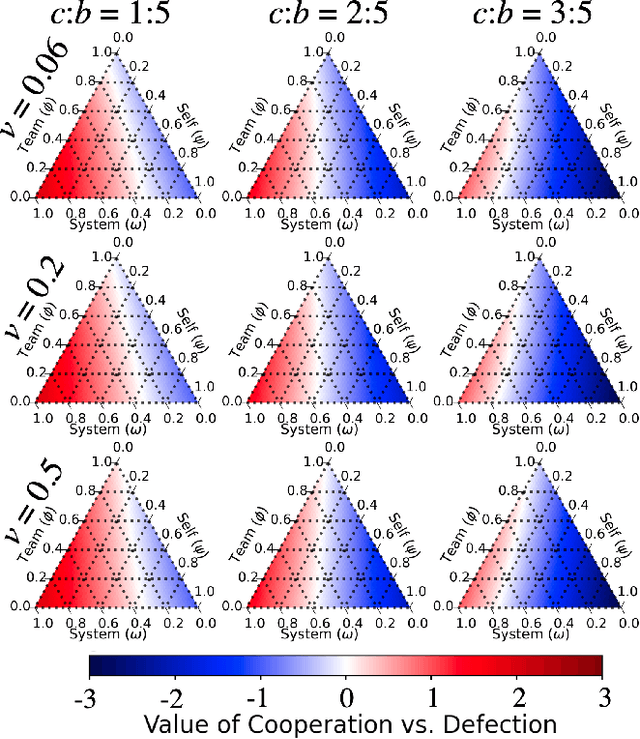
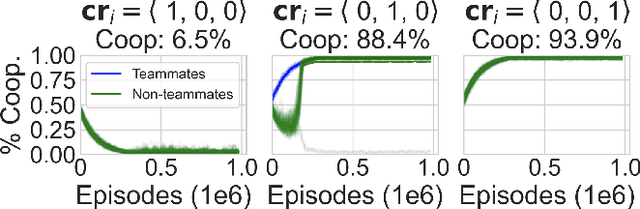
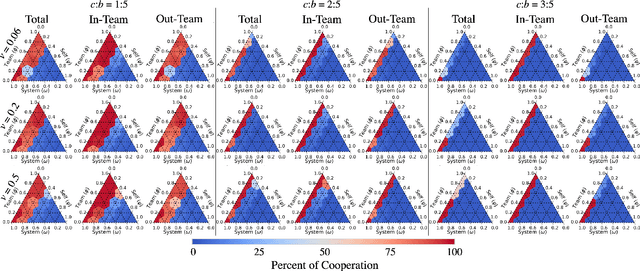
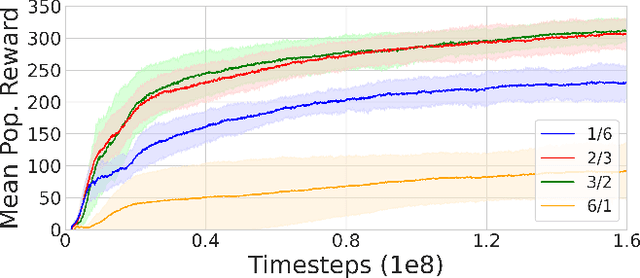
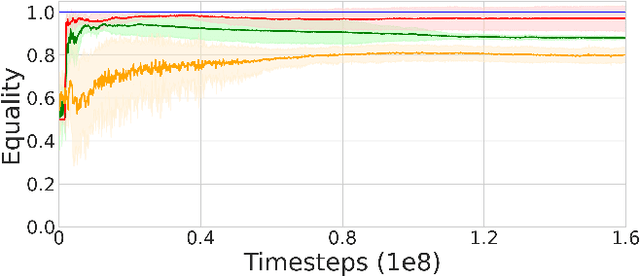
We propose a model for multi-objective optimization, a credo, for agents in a system that are configured into multiple groups (i.e., teams). Our model of credo regulates how agents optimize their behavior for the component groups they belong to. We evaluate credo in the context of challenging social dilemmas with reinforcement learning agents. Our results indicate that the interests of teammates, or the entire system, are not required to be fully aligned for globally beneficial outcomes. We identify two scenarios without full common interest that achieve high equality and significantly higher mean population rewards compared to when the interests of all agents are aligned.