Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Credo in Multiagent Learning
Paper and Code

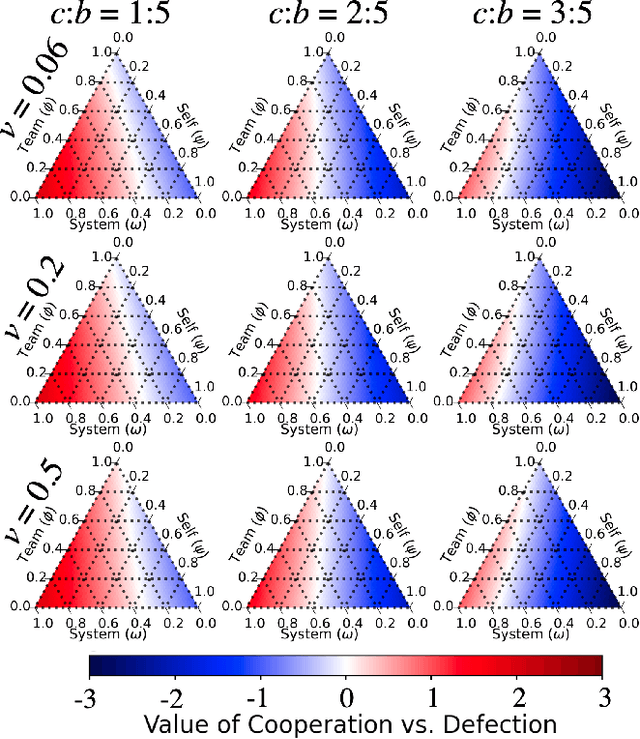
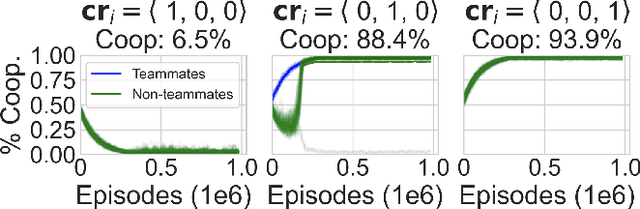
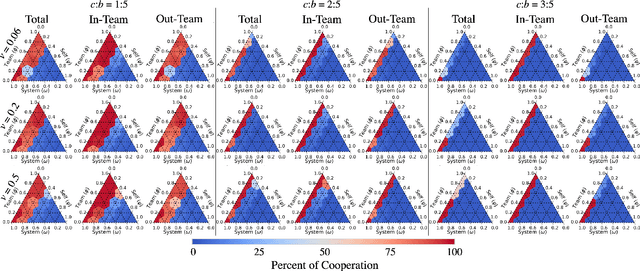
We propose a model for multi-objective optimization, a credo, for agents in a system that are configured into multiple groups (i.e., teams). Our model of credo regulates how agents optimize their behavior for the component groups they belong to. We evaluate credo in the context of challenging social dilemmas with reinforcement learning agents. Our results indicate that the interests of teammates, or the entire system, are not required to be fully aligned for globally beneficial outcomes. We identify two scenarios without full common interest that achieve high equality and significantly higher mean population rewards compared to when the interests of all agents are aligned.
* 8 pages, 7 figures, Proceedings of the Adaptive and Learning Agents
Workshop (ALA 2022) at AAMAS 2022
View paper on