 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytically Tractable Bayesian Deep Q-Learning
Jun 21, 2021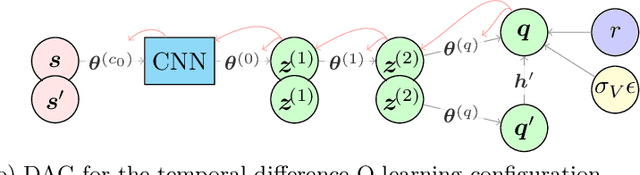


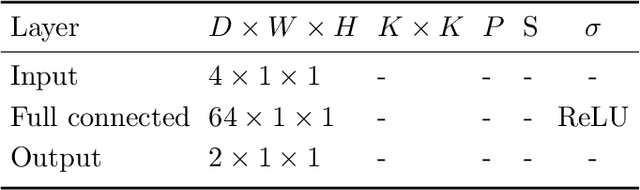
Reinforcement learning (RL) has gained increasing interest since the demonstration it was able to reach human performance on video game benchmarks using deep Q-learning (DQN). The current consensus for training neural networks on such complex environments is to rely on gradient-based optimization. Although alternative Bayesian deep learning methods exist, most of them still rely on gradient-based optimization, and they typically do not scale on benchmarks such as the Atari game environment. Moreover none of these approaches allow performing the analytical inference for the weights and biases defining the neural network. In this paper, we present how we can adapt the temporal difference Q-learning framework to make it compatible with the tractable approximate Gaussian inference (TAGI), which allows learning the parameters of a neural network using a closed-form analytical method. Throughout the experiments with on- and off-policy reinforcement learning approaches, we demonstrate that TAGI can reach a performance comparable to backpropagation-trained networks while using fewer hyperparameters, and without relying on gradient-based optimization.