 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabricFlowNet: Bimanual Cloth Manipulation with a Flow-based Policy
Nov 10, 2021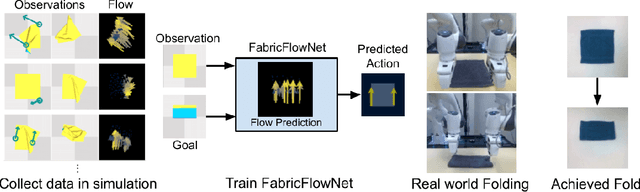

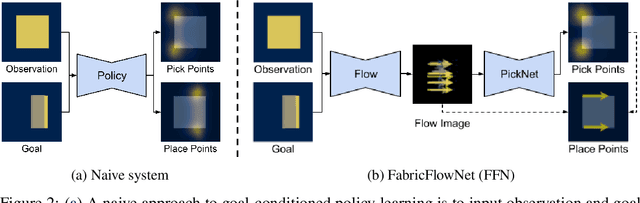

We address the problem of goal-directed cloth manipulation, a challenging task due to the deformability of cloth. Our insight is that optical flow, a technique normally used for motion estimation in video, can also provide an effective representation for corresponding cloth poses across observation and goal images. We introduce FabricFlowNet (FFN), a cloth manipulation policy that leverages flow as both an input and as an action representation to improve performance. FabricFlowNet also elegantly switches between bimanual and single-arm actions based on the desired goal. We show that FabricFlowNet significantly outperforms state-of-the-art model-free and model-based cloth manipulation policies that take image input. We also present real-world experiments on a bimanual system, demonstrating effective sim-to-real transfer. Finally, we show that our method generalizes when trained on a single square cloth to other cloth shapes, such as T-shirts and rectangular cloths. Video and other supplementary materials are available at: https://sites.google.com/view/fabricflownet.
PLAS: Latent Action Space for Offline Reinforcement Learning
Nov 14, 2020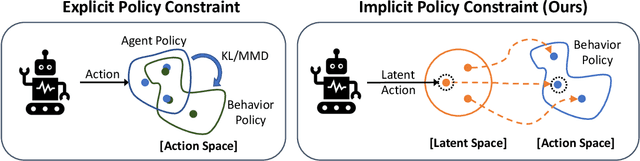
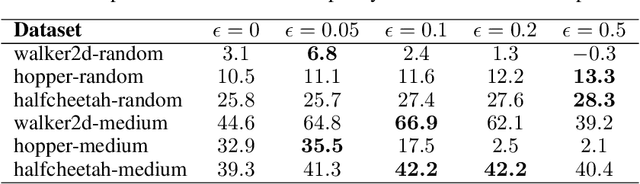

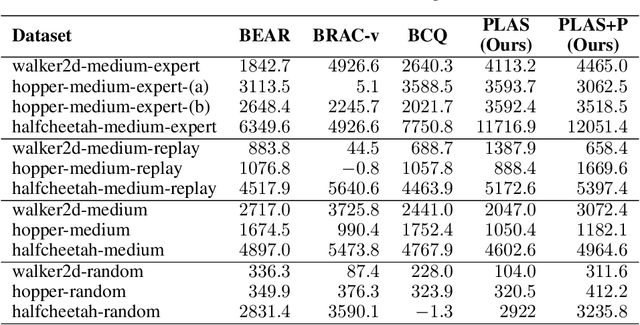
The goal of offline reinforcement learning is to learn a policy from a fixed dataset, without further interactions with the environment. This setting will be an increasingly more important paradigm for real-world applications of reinforcement learning such as robotics, in which data collection is slow and potentially dangerous. Existing off-policy algorithms have limited performance on static datasets due to extrapolation errors from out-of-distribution actions. This leads to the challenge of constraining the policy to select actions within the support of the dataset during training. We propose to simply learn the Policy in the Latent Action Space (PLAS) such that this requirement is naturally satisfied. We evaluate our method on continuous control benchmarks in simulation and a deformable object manipulation task with a physical robot. We demonstrate that our method provides competitive performance consistently across various continuous control tasks and different types of datasets, outperforming existing offline reinforcement learning methods with explicit constraints. Videos and code are available at https://sites.google.com/view/latent-policy.
Augmenting Knowledge through Statistical, Goal-oriented Human-Robot Dialog
Jul 08, 2019
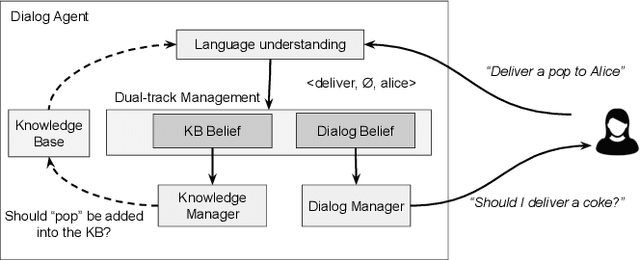
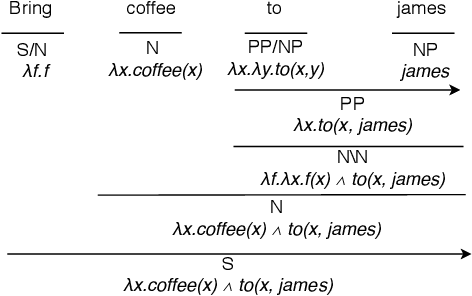
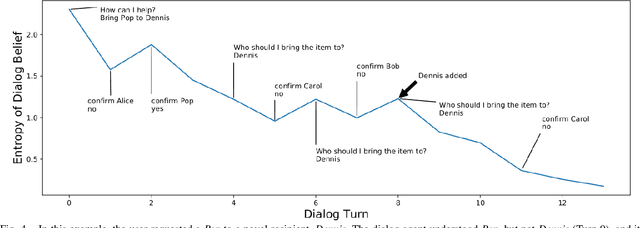
Some robots can interact with humans using natural language, and identify service requests through human-robot dialog. However, few robots are able to improve their language capabilities from this experience. In this paper, we develop a dialog agent for robots that is able to interpret user commands using a semantic parser, while asking clarification questions using a probabilistic dialog manager. This dialog agent is able to augment its knowledge base and improve its language capabilities by learning from dialog experiences, e.g., adding new entities and learning new ways of referring to existing entities. We have extensively evaluated our dialog system in simulation as well as with human participants through MTurk and real-robot platforms. We demonstrate that our dialog agent performs better in efficiency and accuracy in comparison to baseline learning agents. Demo video can be found at https://youtu.be/DFB3jbHBqYE