 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLAS: Latent Action Space for Offline Reinforcement Learning
Paper and Code
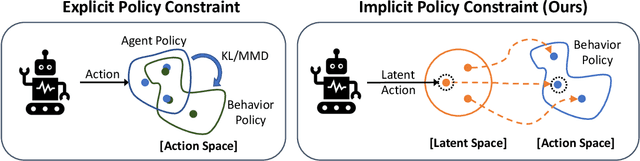
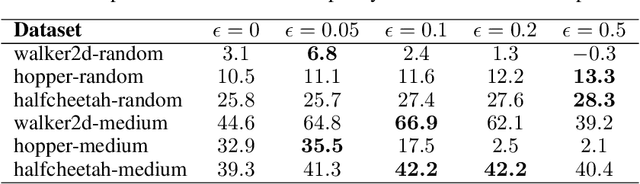

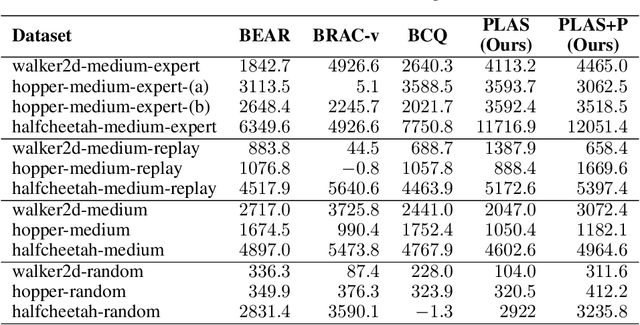
The goal of offline reinforcement learning is to learn a policy from a fixed dataset, without further interactions with the environment. This setting will be an increasingly more important paradigm for real-world applications of reinforcement learning such as robotics, in which data collection is slow and potentially dangerous. Existing off-policy algorithms have limited performance on static datasets due to extrapolation errors from out-of-distribution actions. This leads to the challenge of constraining the policy to select actions within the support of the dataset during training. We propose to simply learn the Policy in the Latent Action Space (PLAS) such that this requirement is naturally satisfied. We evaluate our method on continuous control benchmarks in simulation and a deformable object manipulation task with a physical robot. We demonstrate that our method provides competitive performance consistently across various continuous control tasks and different types of datasets, outperforming existing offline reinforcement learning methods with explicit constraints. Videos and code are available at https://sites.google.com/view/latent-policy.