 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Traffic Signals for Daily Traffic Pattern
Jun 26, 2025



The turning movement count data is crucial for traffic signal design, intersection geometry planning, traffic flow, and congestion analysis. This work proposes three methods called dynamic, static, and hybrid configuration for TMC-based traffic signals. A vision-based tracking system is developed to estimate the TMC of six intersections in Las Vegas using traffic cameras. The intersection design, route (e.g. vehicle movement directions), and signal configuration files with compatible formats are synthesized and imported into Simulation of Urban MObility for signal evaluation with realistic data. The initial experimental results based on estimated waiting times indicate that the cycle time of 90 and 120 seconds works best for all intersections. In addition, four intersections show better performance for dynamic signal timing configuration, and the other two with lower performance have a lower ratio of total vehicle count to total lanes of the intersection leg. Since daily traffic flow often exhibits a bimodal pattern, we propose a hybrid signal method that switches between dynamic and static methods, adapting to peak and off-peak traffic conditions for improved flow management. So, a built-in traffic generator module creates vehicle routes for 4 hours, including peak hours, and a signal design module produces signal schedule cycles according to static, dynamic, and hybrid methods. Vehicle count distributions are weighted differently for each zone (i.e., West, North, East, South) to generate diverse traffic patterns. The extended experimental results for 6 intersections with 4 hours of simulation time imply that zone-based traffic pattern distributions affect signal design selection. Although the static method works great for evenly zone-based traffic distribution, the hybrid method works well for highly weighted traffic at intersection pairs of the West-East and North-South zones.
A Systematic Approach for Assessing Large Language Models' Test Case Generation Capability
Feb 05, 2025



Software testing ensures the quality and reliability of software products, but manual test case creation is labor-intensive. With the rise of large language models (LLMs), there is growing interest in unit test creation with LLMs. However, effective assessment of LLM-generated test cases is limited by the lack of standardized benchmarks that comprehensively cover diverse programming scenarios. To address the assessment of LLM's test case generation ability and lacking dataset for evaluation, we propose the Generated Benchmark from Control-Flow Structure and Variable Usage Composition (GBCV) approach, which systematically generates programs used for evaluating LLMs' test generation capabilities. By leveraging basic control-flow structures and variable usage, GBCV provides a flexible framework to create a spectrum of programs ranging from simple to complex. Because GPT-4o and GPT-3-Turbo are publicly accessible models, to present real-world regular user's use case, we use GBCV to assess LLM performance on them. Our findings indicate that GPT-4o performs better on complex program structures, while all models effectively detect boundary values in simple conditions but face challenges with arithmetic computations. This study highlights the strengths and limitations of LLMs in test generation, provides a benchmark framework, and suggests directions for future improvement.
Robot Sequential Decision Making using LSTM-based Learning and Logical-probabilistic Reasoning
Jan 16, 2019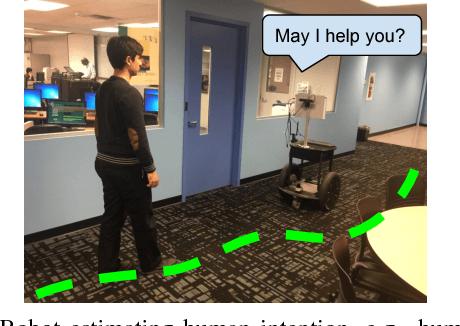

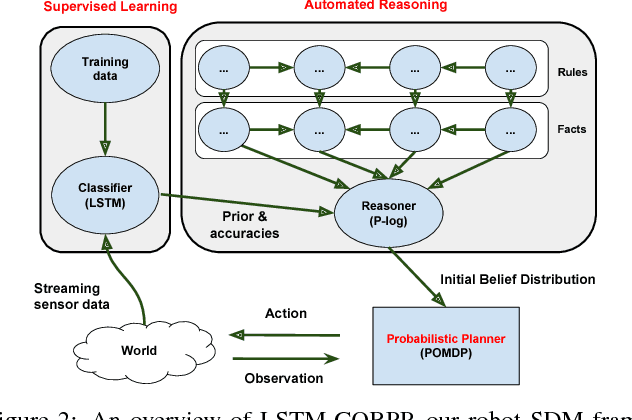
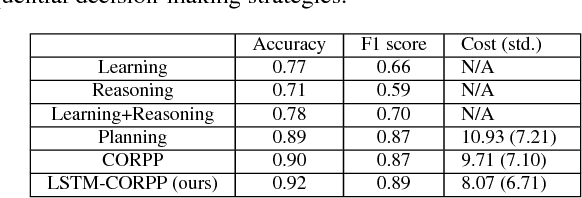
Sequential decision-making (SDM) plays a key role in intelligent robotics, and can be realized in very different ways, such as supervised learning, automated reasoning, and probabilistic planning. The three families of methods follow different assumptions and have different (dis)advantages. In this work, we aim at a robot SDM framework that exploits the complementary features of learning, reasoning, and planning. We utilize long short-term memory (LSTM), for passive state estimation with streaming sensor data, and commonsense reasoning and probabilistic planning (CORPP) for active information collection and task accomplishment. In experiments, a mobile robot is tasked with estimating human intentions using their motion trajectories, declarative contextual knowledge, and human-robot interaction (dialog-based and motion-based). Results suggest that our framework performs better than its no-learning and no-reasoning versions in a real-world office environment.