 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARDIE: AR, Dialogue, and Eye Gaze Policies for Human-Robot Collaboration
May 08, 2023

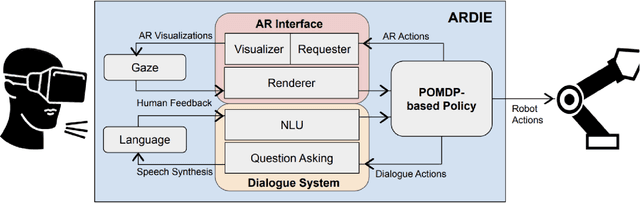
Human-robot collaboration (HRC) has become increasingly relevant in industrial, household, and commercial settings. However, the effectiveness of such collaborations is highly dependent on the human and robots' situational awareness of the environment. Improving this awareness includes not only aligning perceptions in a shared workspace, but also bidirectionally communicating intent and visualizing different states of the environment to enhance scene understanding. In this paper, we propose ARDIE (Augmented Reality with Dialogue and Eye Gaze), a novel intelligent agent that leverages multi-modal feedback cues to enhance HRC. Our system utilizes a decision theoretic framework to formulate a joint policy that incorporates interactive augmented reality (AR), natural language, and eye gaze to portray current and future states of the environment. Through object-specific AR renders, the human can visualize future object interactions to make adjustments as needed, ultimately providing an interactive and efficient collaboration between humans and robots.
Learning Visualization Policies of Augmented Reality for Human-Robot Collaboration
Nov 13, 2022In human-robot collaboration domains, augmented reality (AR) technologies have enabled people to visualize the state of robots. Current AR-based visualization policies are designed manually, which requires a lot of human efforts and domain knowledge. When too little information is visualized, human users find the AR interface not useful; when too much information is visualized, they find it difficult to process the visualized information. In this paper, we develop a framework, called VARIL, that enables AR agents to learn visualization policies (what to visualize, when, and how) from demonstrations. We created a Unity-based platform for simulating warehouse environments where human-robot teammates collaborate on delivery tasks. We have collected a dataset that includes demonstrations of visualizing robots' current and planned behaviors. Results from experiments with real human participants show that, compared with competitive baselines from the literature, our learned visualization strategies significantly increase the efficiency of human-robot teams, while reducing the distraction level of human users. VARIL has been demonstrated in a built-in-lab mock warehouse.
Reasoning with Scene Graphs for Robot Planning under Partial Observability
Feb 21, 2022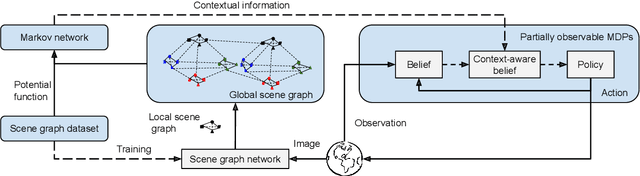
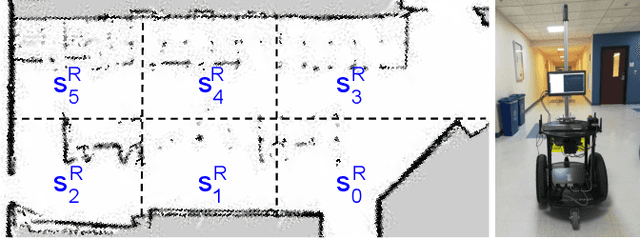
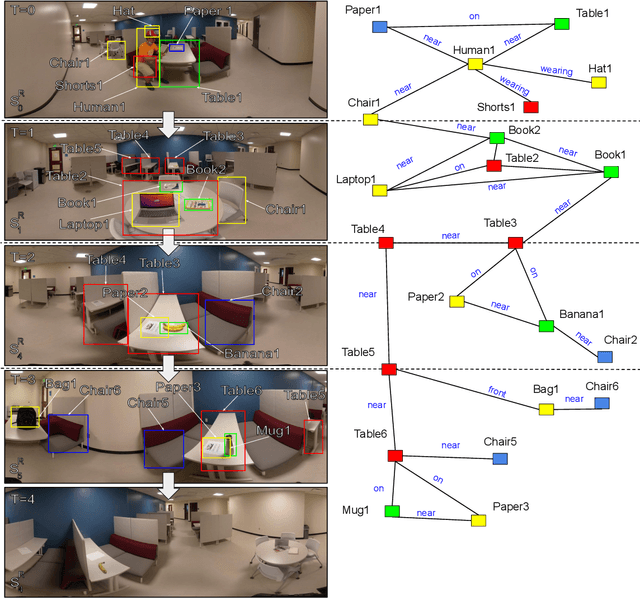

Robot planning in partially observable domains is difficult, because a robot needs to estimate the current state and plan actions at the same time. When the domain includes many objects, reasoning about the objects and their relationships makes robot planning even more difficult. In this paper, we develop an algorithm called scene analysis for robot planning (SARP) that enables robots to reason with visual contextual information toward achieving long-term goals under uncertainty. SARP constructs scene graphs, a factored representation of objects and their relations, using images captured from different positions, and reasons with them to enable context-aware robot planning under partial observability. Experiments have been conducted using multiple 3D environments in simulation, and a dataset collected by a real robot. In comparison to standard robot planning and scene analysis methods, in a target search domain, SARP improves both efficiency and accuracy in task completion. Supplementary material can be found at https://tinyurl.com/sarp22
ARROCH Augmented Reality for Robots Collaborating with a Human
Sep 21, 2021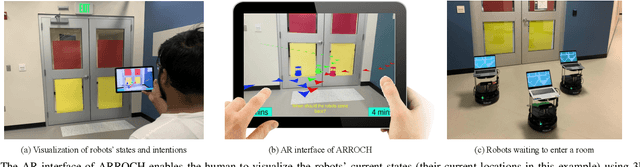


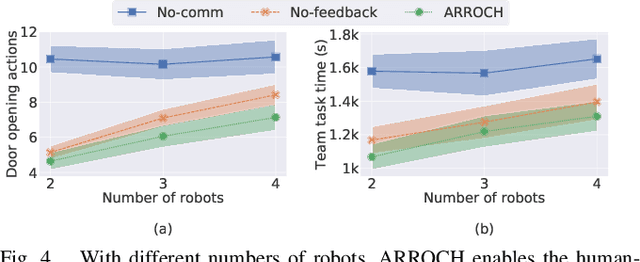
Human-robot collaboration frequently requires extensive communication, e.g., using natural language and gestures. Augmented reality (AR) has provided an alternative way of bridging the communication gap between robots and people. However, most current AR-based human-robot communication methods are unidirectional, focusing on how the human adapts to robot behaviors, and are limited to single-robot domains. In this paper, we develop AR for Robots Collaborating with a Human (ARROCH), a novel algorithm and system that supports bidirectional, multi-turn, human-multi-robot communication in indoor multi-room environments. The human can see through obstacles to observe the robots' current states and intentions, and provide feedback, while the robots' behaviors are then adjusted toward human-multi-robot teamwork. Experiments have been conducted with real robots and human participants using collaborative delivery tasks. Results show that ARROCH outperformed a standard non-AR approach in both user experience and teamwork efficiency. In addition, we have developed a novel simulation environment using Unity (for AR and human simulation) and Gazebo (for robot simulation). Results in simulation demonstrate ARROCH's superiority over AR-based baselines in human-robot collaboration.
Learning to Guide Human Attention on Mobile Telepresence Robots with 360 degree Vision
Sep 21, 2021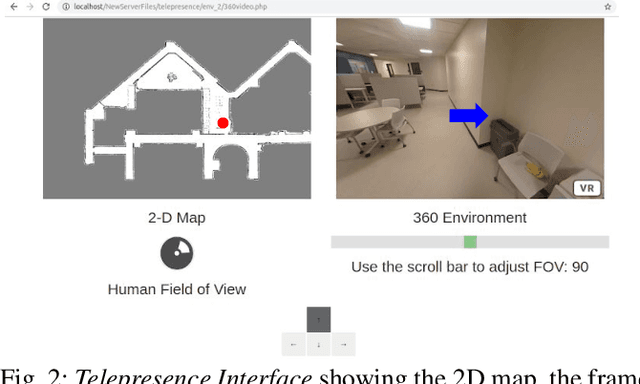


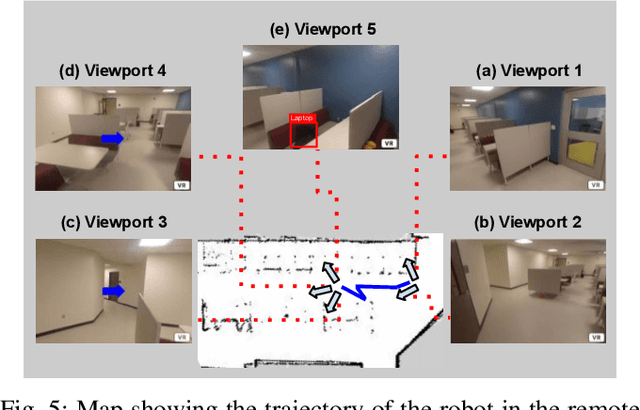
Mobile telepresence robots (MTRs) allow people to navigate and interact with a remote environment that is in a place other than the person's true location. Thanks to the recent advances in 360 degree vision, many MTRs are now equipped with an all-degree visual perception capability. However, people's visual field horizontally spans only about 120 degree of the visual field captured by the robot. To bridge this observability gap toward human-MTR shared autonomy, we have developed a framework, called GHAL360, to enable the MTR to learn a goal-oriented policy from reinforcements for guiding human attention using visual indicators. Three telepresence environments were constructed using datasets that are extracted from Matterport3D and collected from a real robot respectively. Experimental results show that GHAL360 outperformed the baselines from the literature in the efficiency of a human-MTR team completing target search tasks.
Guided Dyna-Q for Mobile Robot Exploration and Navigation
Apr 23, 2020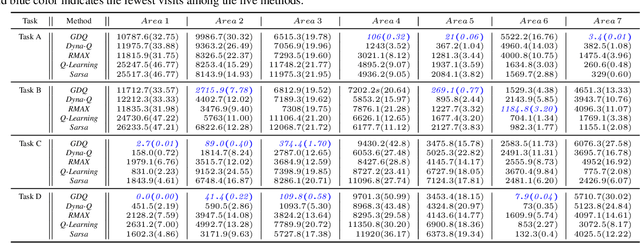
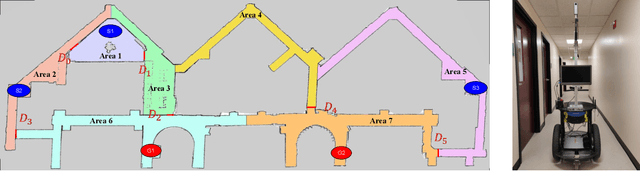
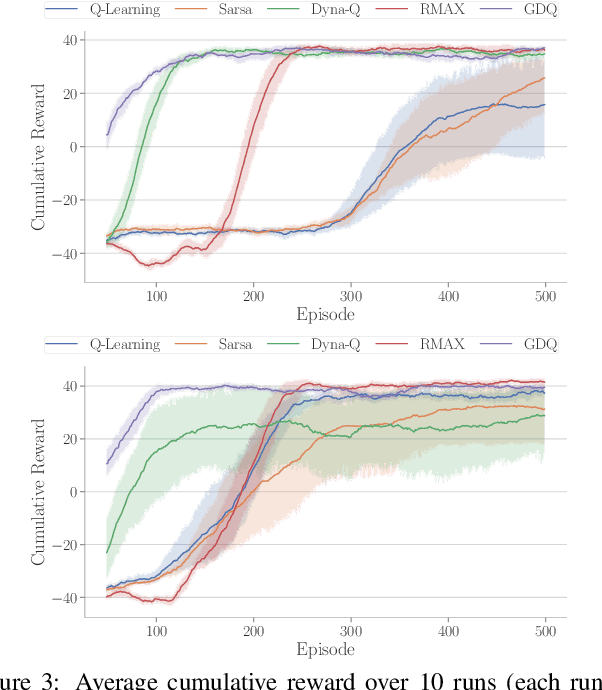
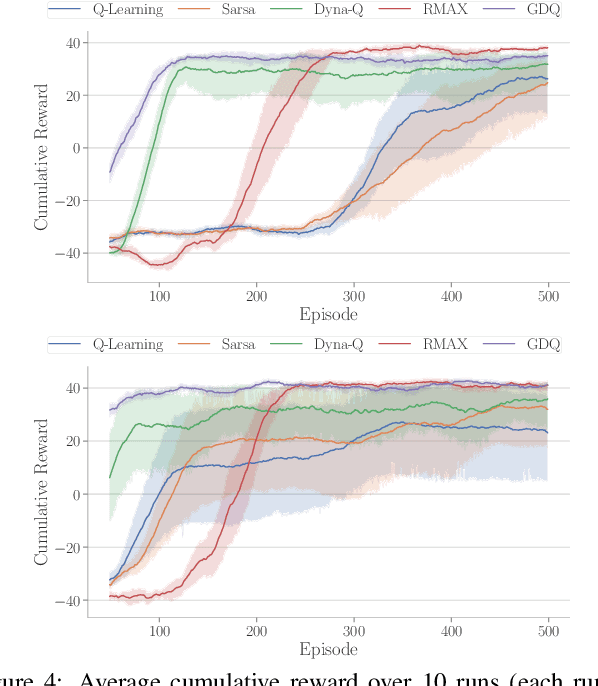
Model-based reinforcement learning (RL) enables an agent to learn world models from trial-and-error experiences toward achieving long-term goals. Automated planning, on the other hand, can be used for accomplishing tasks through reasoning with declarative action knowledge. Despite their shared goal of completing complex tasks, the development of RL and automated planning has mainly been isolated due to their different modalities of computation. Focusing on improving model-based RL agent's exploration strategy and sample efficiency, we develop Guided Dyna-Q (GDQ) to enable RL agents to reason with action knowledge to avoid exploring less-relevant states toward more efficient task accomplishment. GDQ has been evaluated in simulation and using a mobile robot conducting navigation tasks in an office environment. Results show that GDQ reduces the effort in exploration while improving the quality of learned policies.
Negotiation-based Human-Robot Collaboration via Augmented Reality
Sep 24, 2019

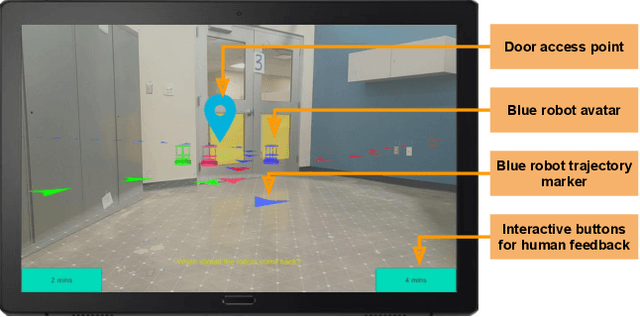

Effective human-robot collaboration (HRC) requires extensive communication among the human and robot teammates, because their actions can potentially produce conflicts, synergies, or both. In this paper, we develop an augmented reality-driven, negotiation-based (ARN) framework for HRC, where ARN supports planning-phase negotiations within human-robot teams through a novel AR-based interface. We have conducted experiments in an office environment, where multiple mobile robots work on delivery tasks. The robots could not complete the tasks on their own, but sometimes need help from their human teammate, rendering human-robot collaboration necessary. From the experimental results, we observe that ARN significantly reduced the human-robot team's task completion time in comparison to a non-AR baseline.