 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalBench: Evaluating Coordination-Privacy Trade-offs in Multi-Agent LLMs
May 10, 2026We introduce CalBench, a controlled evaluation environment for studying multi-agent coordination through calendar scheduling. In CalBench, N agents each manage a private calendar containing pre-existing commitments and must coordinate to schedule a stream of M incoming meetings while minimizing disruption costs. Because agents observe only their own calendars, successful scheduling requires communication across private information boundaries. Each scenario is generated with an oracle solution, enabling precise measurement of coordination quality via realized-to-optimal cost, as well as a Distributed Constraint Optimization (DCOP) baseline to provide a fair comparison under the same private-information constraints. CalBench enables precise verification of task success, communication efficiency, and fairness in the distribution of disruption costs. Our environment also studies privacy-preserving coordination by augmenting calendar entries with private semantic contexts of varying sensitivity and measuring whether agents reveal task-irrelevant private information during negotiation. Unlike multi-agent benchmarks where a single capable agent can often substitute for the group, CalBench is inherently decentralized: no agent has access to another agent's private calendar, yet agents must still reach mutually consistent decisions over shared meeting scheduling. CalBench therefore provides a practical and verifiable setting for studying coordination protocols, communication efficiency, negotiation strategies, fairness, and privacy leakage in multi-agent systems.
Talk is Cheap, Communication is Hard: Dynamic Grounding Failures and Repair in Multi-Agent Negotiation
May 03, 2026Grounding is the collaborative process of establishing mutual belief sufficient for the current communicative purpose. While static grounding maps language to a shared, externally observable context, dynamic grounding is a joint activity where meaning is negotiated through interaction. Current multi-agent Large Language Model (LLM) benchmarks focus on static, one-shot tasks, overlooking the ability to repair grounding breakdowns across turns. We introduce an iterated, multi-turn negotiation game in which two agents allocate shared resources toward private projects with verifiable jointly optimal outcomes. While individual agents can identify Pareto-optimal allocations in isolation, agent dyads consistently fail to reach them across open- and closed-source models. Our investigation reveals four failure modes: (1) coordination degrades when shared interaction history is absent; (2) yet accumulated context can itself become a liability through stubborn anchoring, where initial proposals are treated as axiomatic rather than negotiable; (3) a reliance on perfunctory fairness (equal resource splits) over reward-maximizing coordination; and (4) failures in referential binding, where agents lose track of commitments across turns. These results highlight dynamic grounding as a critical and understudied axis of multi-agent coordination. Our framework decomposes the coordination gap into measurable components: the oracle baseline establishes that the gap is not attributable to individual reasoning limitations; the no-talk baseline establishes that communication is necessary; and a full-transparency intervention establishes that information exchange alone is insufficient: the bottleneck lies in the interactive processes of joint plan formation, commitment, and execution that constitute dynamic grounding.
A Unified Definition of Hallucination, Or: It's the World Model, Stupid
Dec 25, 2025Despite numerous attempts to solve the issue of hallucination since the inception of neural language models, it remains a problem in even frontier large language models today. Why is this the case? We walk through definitions of hallucination used in the literature from a historical perspective up to the current day, and fold them into a single definition of hallucination, wherein different prior definitions focus on different aspects of our definition. At its core, we argue that hallucination is simply inaccurate (internal) world modeling, in a form where it is observable to the user (e.g., stating a fact which contradicts a knowledge base, or producing a summary which contradicts a known source). By varying the reference world model as well as the knowledge conflict policy (e.g., knowledge base vs. in-context), we arrive at the different existing definitions of hallucination present in the literature. We argue that this unified view is useful because it forces evaluations to make clear their assumed "world" or source of truth, clarifies what should and should not be called hallucination (as opposed to planning or reward/incentive-related errors), and provides a common language to compare benchmarks and mitigation techniques. Building on this definition, we outline plans for a family of benchmarks in which hallucinations are defined as mismatches with synthetic but fully specified world models in different environments, and sketch out how these benchmarks can use such settings to stress-test and improve the world modeling components of language models.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Abstracted Gaussian Prototypes for One-Shot Concept Learning
Aug 30, 2024



We introduce a cluster-based generative image segmentation framework to encode higher-level representations of visual concepts based on one-shot learning inspired by the Omniglot Challenge. The inferred parameters of each component of a Gaussian Mixture Model (GMM) represent a distinct topological subpart of a visual concept. Sampling new data from these parameters generates augmented subparts to build a more robust prototype for each concept, i.e., the Abstracted Gaussian Prototype (AGP). This framework addresses one-shot classification tasks using a cognitively-inspired similarity metric and addresses one-shot generative tasks through a novel AGP-VAE pipeline employing variational autoencoders (VAEs) to generate new class variants. Results from human judges reveal that the generative pipeline produces novel examples and classes of visual concepts that are broadly indistinguishable from those made by humans. The proposed framework leads to impressive but not state-of-the-art classification accuracy; thus, the contribution is two-fold: 1) the system is uniquely low in theoretical and computational complexity and operates in a completely standalone manner compared while existing approaches draw heavily on pre-training or knowledge engineering; and 2) in contrast with competing neural network models, the AGP approach addresses the importance of breadth of task capability emphasized in the Omniglot challenge (i.e., successful performance on generative tasks). These two points are critical as we advance toward an understanding of how learning/reasoning systems can produce viable, robust, and flexible concepts based on literally nothing more than a single example.
ARDIE: AR, Dialogue, and Eye Gaze Policies for Human-Robot Collaboration
May 08, 2023

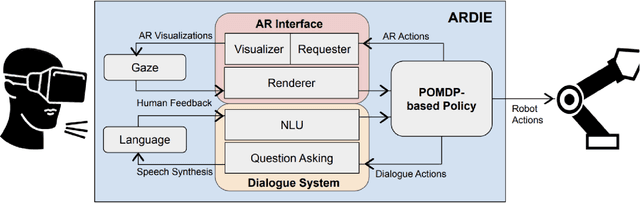
Human-robot collaboration (HRC) has become increasingly relevant in industrial, household, and commercial settings. However, the effectiveness of such collaborations is highly dependent on the human and robots' situational awareness of the environment. Improving this awareness includes not only aligning perceptions in a shared workspace, but also bidirectionally communicating intent and visualizing different states of the environment to enhance scene understanding. In this paper, we propose ARDIE (Augmented Reality with Dialogue and Eye Gaze), a novel intelligent agent that leverages multi-modal feedback cues to enhance HRC. Our system utilizes a decision theoretic framework to formulate a joint policy that incorporates interactive augmented reality (AR), natural language, and eye gaze to portray current and future states of the environment. Through object-specific AR renders, the human can visualize future object interactions to make adjustments as needed, ultimately providing an interactive and efficient collaboration between humans and robots.