 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
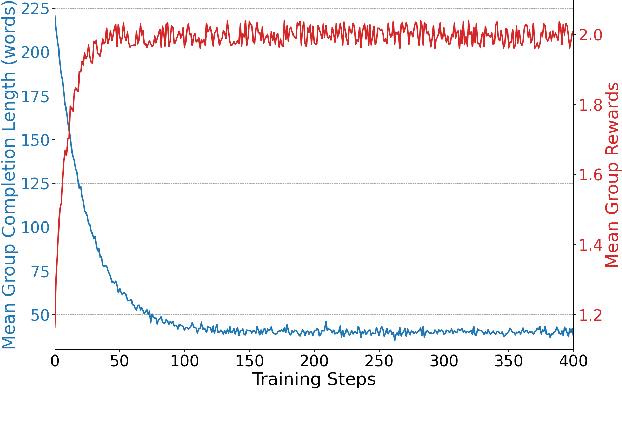
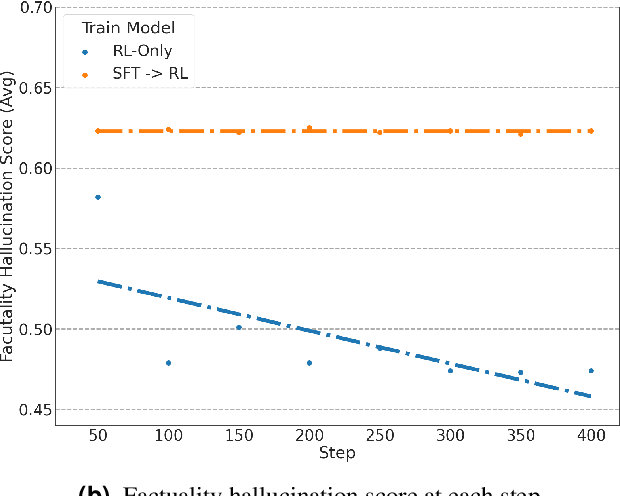
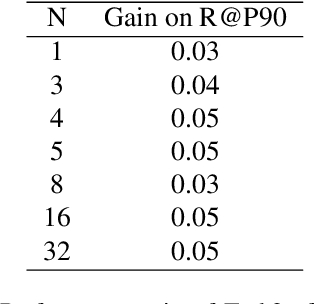
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
SGDFuse: SAM-Guided Diffusion for High-Fidelity Infrared and Visible Image Fusion
Aug 07, 2025Infrared and visible image fusion (IVIF) aims to combine the thermal radiation information from infrared images with the rich texture details from visible images to enhance perceptual capabilities for downstream visual tasks. However, existing methods often fail to preserve key targets due to a lack of deep semantic understanding of the scene, while the fusion process itself can also introduce artifacts and detail loss, severely compromising both image quality and task performance. To address these issues, this paper proposes SGDFuse, a conditional diffusion model guided by the Segment Anything Model (SAM), to achieve high-fidelity and semantically-aware image fusion. The core of our method is to utilize high-quality semantic masks generated by SAM as explicit priors to guide the optimization of the fusion process via a conditional diffusion model. Specifically, the framework operates in a two-stage process: it first performs a preliminary fusion of multi-modal features, and then utilizes the semantic masks from SAM jointly with the preliminary fused image as a condition to drive the diffusion model's coarse-to-fine denoising generation. This ensures the fusion process not only has explicit semantic directionality but also guarantees the high fidelity of the final result. Extensive experiments demonstrate that SGDFuse achieves state-of-the-art performance in both subjective and objective evaluations, as well as in its adaptability to downstream tasks, providing a powerful solution to the core challenges in image fusion. The code of SGDFuse is available at https://github.com/boshizhang123/SGDFuse.
Wavelet-Guided Dual-Frequency Encoding for Remote Sensing Change Detection
Aug 07, 2025Change detection in remote sensing imagery plays a vital role in various engineering applications, such as natural disaster monitoring, urban expansion tracking, and infrastructure management. Despite the remarkable progress of deep learning in recent years, most existing methods still rely on spatial-domain modeling, where the limited diversity of feature representations hinders the detection of subtle change regions. We observe that frequency-domain feature modeling particularly in the wavelet domain an amplify fine-grained differences in frequency components, enhancing the perception of edge changes that are challenging to capture in the spatial domain. Thus, we propose a method called Wavelet-Guided Dual-Frequency Encoding (WGDF). Specifically, we first apply Discrete Wavelet Transform (DWT) to decompose the input images into high-frequency and low-frequency components, which are used to model local details and global structures, respectively. In the high-frequency branch, we design a Dual-Frequency Feature Enhancement (DFFE) module to strengthen edge detail representation and introduce a Frequency-Domain Interactive Difference (FDID) module to enhance the modeling of fine-grained changes. In the low-frequency branch, we exploit Transformers to capture global semantic relationships and employ a Progressive Contextual Difference Module (PCDM) to progressively refine change regions, enabling precise structural semantic characterization. Finally, the high- and low-frequency features are synergistically fused to unify local sensitivity with global discriminability. Extensive experiments on multiple remote sensing datasets demonstrate that WGDF significantly alleviates edge ambiguity and achieves superior detection accuracy and robustness compared to state-of-the-art methods. The code will be available at https://github.com/boshizhang123/WGDF.
Learning to Guide Human Attention on Mobile Telepresence Robots with 360 degree Vision
Sep 21, 2021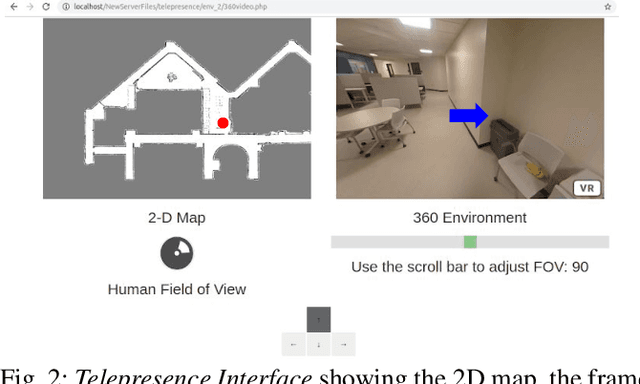


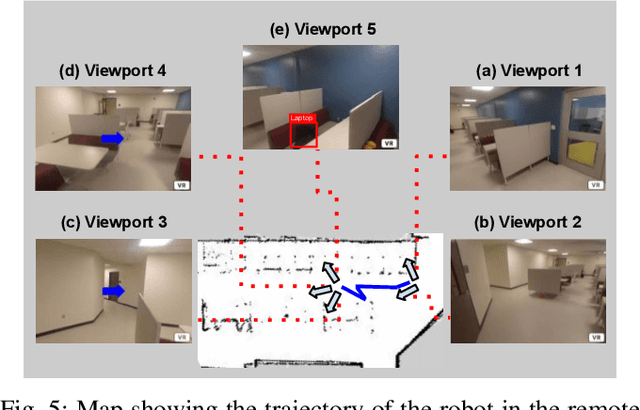
Mobile telepresence robots (MTRs) allow people to navigate and interact with a remote environment that is in a place other than the person's true location. Thanks to the recent advances in 360 degree vision, many MTRs are now equipped with an all-degree visual perception capability. However, people's visual field horizontally spans only about 120 degree of the visual field captured by the robot. To bridge this observability gap toward human-MTR shared autonomy, we have developed a framework, called GHAL360, to enable the MTR to learn a goal-oriented policy from reinforcements for guiding human attention using visual indicators. Three telepresence environments were constructed using datasets that are extracted from Matterport3D and collected from a real robot respectively. Experimental results show that GHAL360 outperformed the baselines from the literature in the efficiency of a human-MTR team completing target search tasks.
I/O Lower Bounds for Auto-tuning of Convolutions in CNNs
Dec 31, 2020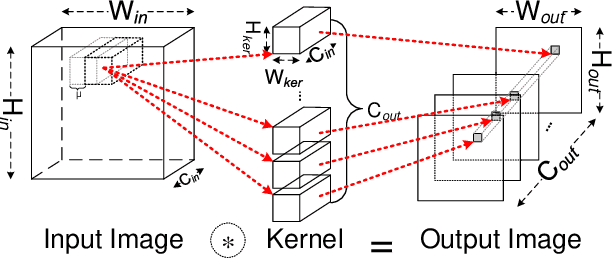
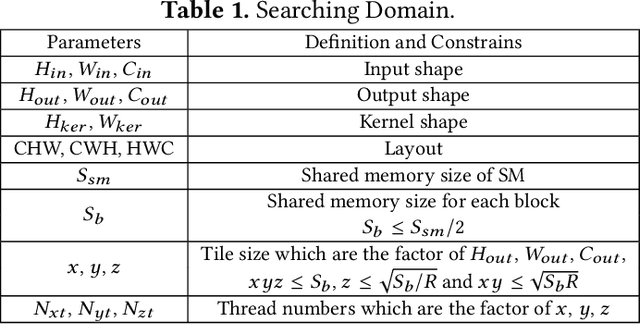
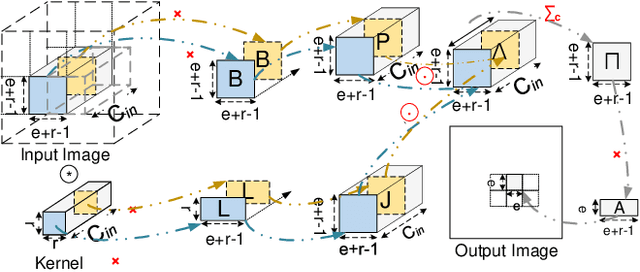

Convolution is the most time-consuming part in the computation of convolutional neural networks (CNNs), which have achieved great successes in numerous applications. Due to the complex data dependency and the increase in the amount of model samples, the convolution suffers from high overhead on data movement (i.e., memory access). This work provides comprehensive analysis and methodologies to minimize the communication for the convolution in CNNs. With an in-depth analysis of the recent I/O complexity theory under the red-blue game model, we develop a general I/O lower bound theory for a composite algorithm which consists of several different sub-computations. Based on the proposed theory, we establish the data movement lower bound results of two representative convolution algorithms in CNNs, namely the direct convolution and Winograd algorithm. Next, derived from I/O lower bound results, we design the near I/O-optimal dataflow strategies for the two main convolution algorithms by fully exploiting the data reuse. Furthermore, in order to push the envelope of performance of the near I/O-optimal dataflow strategies further, an aggressive design of auto-tuning based on I/O lower bounds, is proposed to search an optimal parameter configuration for the direct convolution and Winograd algorithm on GPU, such as the number of threads and the size of shared memory used in each thread block. Finally, experiment evaluation results on the direct convolution and Winograd algorithm show that our dataflow strategies with the auto-tuning approach can achieve about 3.32x performance speedup on average over cuDNN. In addition, compared with TVM, which represents the state-of-the-art technique for auto-tuning, not only our auto-tuning method based on I/O lower bounds can find the optimal parameter configuration faster, but also our solution has higher performance than the optimal solution provided by TVM.