 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting spatio-temporal layouts for compositional action recognition
Paper and Code
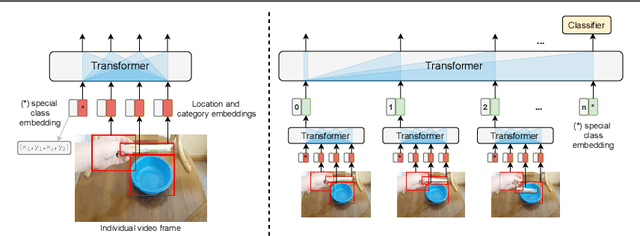
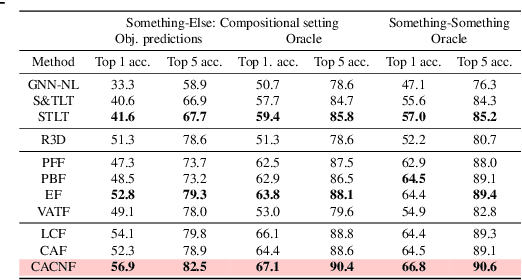
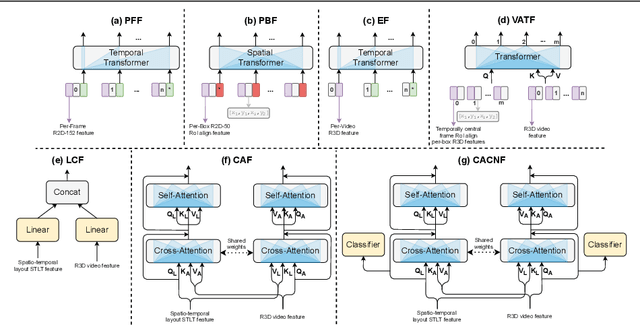
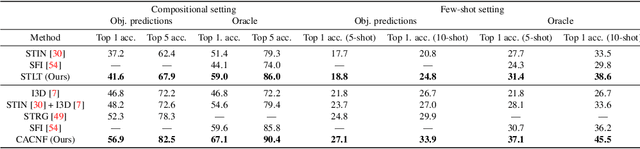
Recognizing human actions is fundamentally a spatio-temporal reasoning problem, and should be, at least to some extent, invariant to the appearance of the human and the objects involved. Motivated by this hypothesis, in this work, we take an object-centric approach to action recognition. Multiple works have studied this setting before, yet it remains unclear (i) how well a carefully crafted, spatio-temporal layout-based method can recognize human actions, and (ii) how, and when, to fuse the information from layout and appearance-based models. The main focus of this paper is compositional/few-shot action recognition, where we advocate the usage of multi-head attention (proven to be effective for spatial reasoning) over spatio-temporal layouts, i.e., configurations of object bounding boxes. We evaluate different schemes to inject video appearance information to the system, and benchmark our approach on background cluttered action recognition. On the Something-Else and Action Genome datasets, we demonstrate (i) how to extend multi-head attention for spatio-temporal layout-based action recognition, (ii) how to improve the performance of appearance-based models by fusion with layout-based models, (iii) that even on non-compositional background-cluttered video datasets, a fusion between layout- and appearance-based models improves the performance.